第二章 - 指令
约 4826 个字 221 行代码 预计阅读时间 19 分钟
计算机语言中的基本单词称作指令 (instruction),一台计算机的全部指令称作该计算机的指令集 (instruction set)。本章将基于 RISC-V 指令系统进行讲解。
计算机硬件的操作数
在 RISC-V 体系结构中,寄存器的大小为 64 位。成组的 64 位在 RISC-V 体系结构中称作双字 (doubleword),成组的 32 位在 RISC-V 体系结构中称作字 (word)。
在当前 RISC-V 计算机上常见 32 个寄存器,约定用 x 后跟一个寄存器编号表示。
以赋值语句
f = (g + h) - (i + j)为例,变量f、g、h、i、j分别分配给寄存器x19、x20、x21、x22、x23。则编译后的 RISC-V 代码为:add x5, x20, x21 // register x5 contains g + h add x6, x22, x23 // register x6 contains i + j sub x19, x5, x6 // f gets x5 - x6, which is (g + h) - (i + j)
存储器操作数
RISC-V 指令中的算术运算只作用于寄存器,因此 RISC-V 必须包含在内存和寄存器之间传输数据的指令,即数据传输指令 (data transfer instructions)。要访问内存中的字或双字,指令必须提供内存地址 (address)。
计算机分为两种,一种使用最左边或大端 (big end) 字节的地址作为双字地址,另一种使用最右端或小端 (little end) 字节的地址作为双字地址。RISC-V 采用的是小端编址。
将数据从内存复制到寄存器的数据传输指令通常称作载入指令 (load)。实际的 RISC-V 指令名称是 ld,表示取双字。
与载入指令相反的指令称作存储指令 (store),其从寄存器复制数据到内存。实际的 RISC-V 指令名称是 sd,表示存双字。
假设变量
h存放在寄存器x21中,数组A的基址 (base address),即起始地址存放在寄存器x22中。编译赋值语句A[12] = h + A[8]得到的 RISC-V 代码为:ld x9, 64(x22) // Temporary reg x9 gets A[8] add x9, x21, x9 // Temporary reg x9 gets h + A[8] sd x9, 96(x22) // Stores h + A[8] back into A[12]其中存放基址的寄存器(
x22)称作基址寄存器 (base register),数据传输指令中的常数(8)称作偏移量 (offset)。其中存放基址的寄存器(
x22)称作基址寄存器 (base register),数据传输指令中的常数(8)称作偏移量 (offset)。
常数或立即数操作数
有时我们希望将变量与常数进行运算,即算术指令的操作数是常数。实际的 RISC-V 指令名称是 addi,称作立即数加 (add immediate)。
假设 变量
h存放在寄存器x22中,编译赋值语句h = h + 4得到的 RISC-V 代码为:addi x22, x22, 4 // h = h + 4
Warning
请注意,没有 subi 指令,减立即数是通过加一个负立即数实现的。
常数操作数在实际指令中经常出现,而常数 \(0\) 尤甚。于是 RISC-V 中专门使用寄存器 x0 作为常 \(0\) 寄存器,即其存放的值始终为 \(0\)。
计算机中的指令表示
计算机识别的指令是有特定的表示方式的,这种指令的设计称作指令格式 (instruction format)。
在 RISC-V 中,所有指令都是 32 位长的二进制数。为了将其和汇编语言区分开来,我们将指令的数字称作机器语言 (machine language),把这样的指令序列称作机器码 (machine code)。
RISC-V 字段
RISC-V 的指令被分为若干个字段 (field)。每个字段具有不同的含义:
- opcode:操作码,用于区分各种指令格式 (instruction format)
- funct3:额外的操作码字段,用于区分属于同一指令格式的不同指令
- funct7:额外的操作码字段,用于区分属于同一指令格式的不同指令
- rd:目的操作数寄存器,用于存放操作结果
- rs1:第一个源操作数寄存器
- rs2:第二个源操作数寄存器
- immediate:立即数,即常数,以二进制补码形式存储
逻辑操作
RISC-V 中也有逻辑操作 (logical operations) 对应的指令。
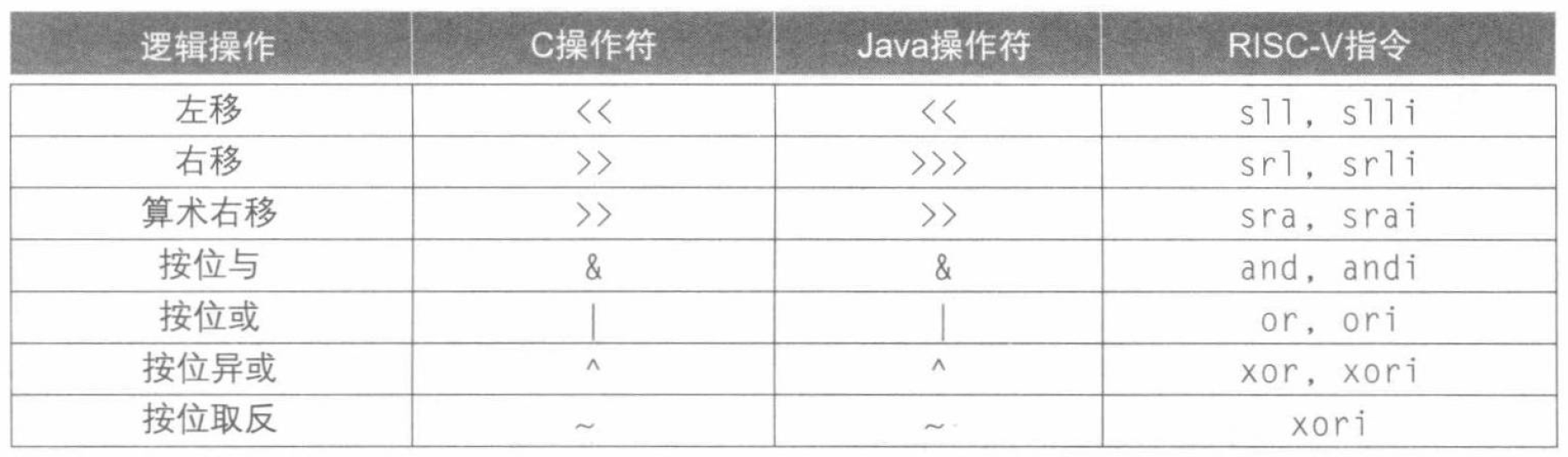
需要注意的是,逻辑右移(srl、srli)用零填充高位(零扩充),算术右移(sra、srai)用符号位填充高位(符号扩充)。
用于决策的指令
计算机与简单计算器的区别在于其决策能力,即能够执行条件分支、循环语句等。在 RISC-V 中,有几类决策指令。
if-then-else 语句
RISC-V 中实现 if-then-else 语句的方法是采用类似于 go to 语句的方式实现的。
beq rs1, rs2, L1
该指令表示如果寄存器 rs1 中的值等于寄存器 rs2 中的值,则转到标签为 L1 的语句执行。这一指令称作相等则分支 (branch if equal)。
bne rs1, rs2, L1
该指令表示如果寄存器 rs1 中的值不等于寄存器 rs2 中的值,则转到标签为 L1 的语句执行。这一指令称作不等则分支 (branch if not equal)。
类似的还有 blt 指令,如果寄存器 rs1 中的值小于寄存器 rs2 中的值则跳转;bge 指令,如果寄存器 rs1 中的值大于等于寄存器 rs2 中的值则跳转。
这些指令都属于条件分支 (conditional branch) 指令。
变量
f到j对应于寄存器x19到x23,编译如下 C 语言代码:if (i == j) { f = g + h; } else { f = g - h; }得到的 RISC-V 代码为:
bne x22, x23, Else // go to Else if i != j add x19, x20, x21 // f = g + h beq x0, x0, Exit // go to Exit if 0 = 0 (unconditional branch) Else: sub x19, x20, x21 // f = g - h Exit:
循环
有了标签和跳转指令,我们也容易得到循环的汇编代码。
变量
i和k对应于寄存器x22到x24,数组的基址保存在x25中,编译如下 C 语言代码:while (save[i] == k) { i += 1; }得到的 RISC-V 代码为:
Loop: slli x10, x22, 3 // Temp reg x10 = i * 8 add x10, x10, x25 // x10 = address of save[i] ld x9, 0(x10) // Temp reg x9 = save[i] bne x9, x24, Exit // go to Exit if save[i] != k addi x22, x22, 1 // i = i + 1 beq x0, x0, Loop // go to Loop Exit:
值得补充的一点是,一个没有分支(除结尾),同时没有分支目标或分支标签(除起始)的指令序列称作基本块 (basic block)。在实际情况中,编译器通过识别出基本块来进行编译的优化,而高级处理器能够加速基本块的执行。
case/switch 语句
大多数编程语言都包含 case 或 switch 语句。一个直观的实现 switch 的方法是将其转化为一系列 if-then-else 语句,但这里我们要介绍一种更有效的方法。
我们使用编码形成指令序列的地址表,这称作分支地址表 (branch address table) 或分支表 (branch table)。程序只需要索引到表中,然后跳转到合适的指令序列。当然,为了支持这一操作,RISC-V 中包含一类间接跳转 (indirect jump) 指令,其使用方式将在后文指出。
计算机硬件对过程的支持
过程 (procedure) 或函数是编程人员用于结构化编程的一种工具,两者均有助于提高程序的可理解性和代码的可重用性。
在执行过程时,程序会遵循以下 6 个步骤:
- 将参数放在过程可以访问到的位置
- 将控制转交给过程
- 获取过程所需的存储资源
- 执行所需的任务
- 将结果值放在调用程序可以访问到的位置
- 将控制返回到初始点,因为过程可以从程序中的多个点调用
跳转-链接指令
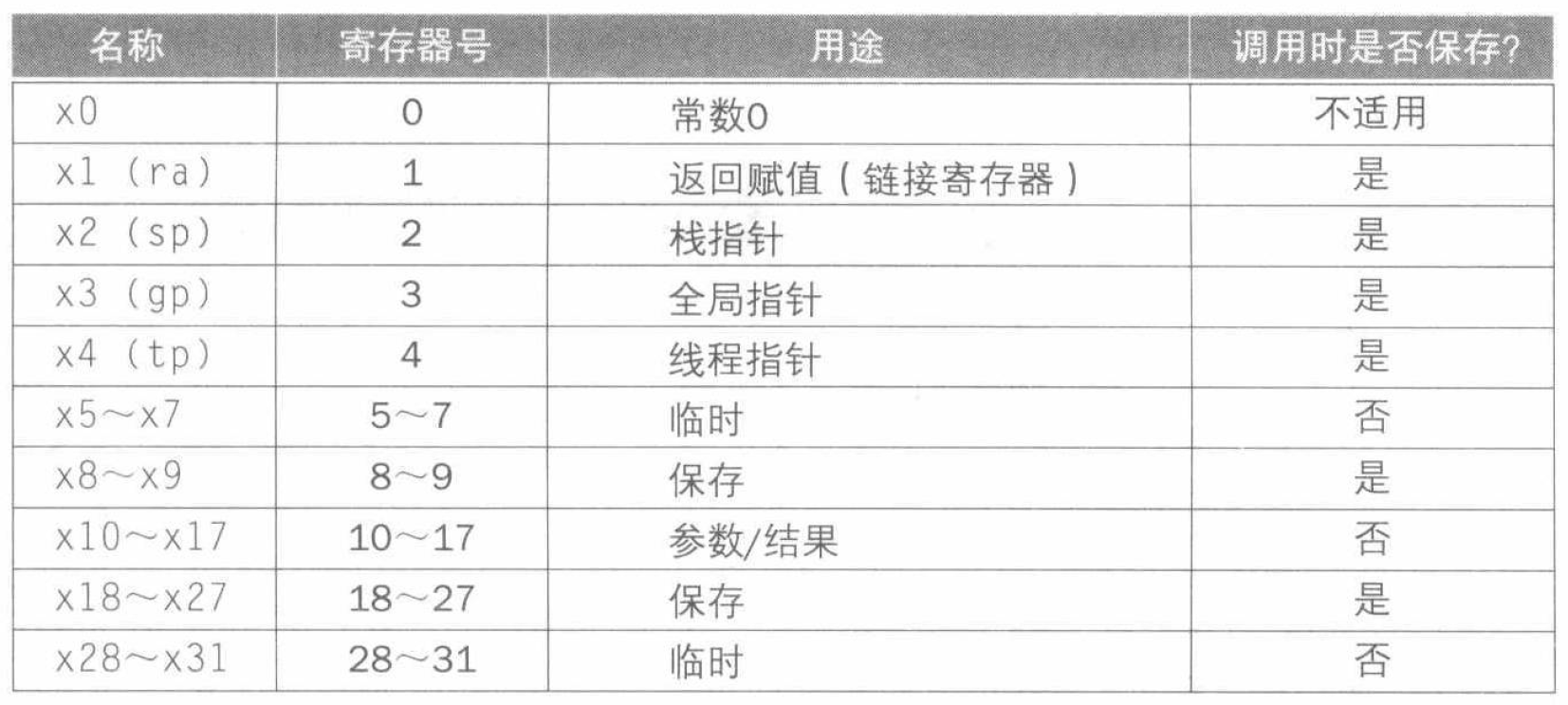
RISC-V 为过程调用分配寄存器时遵循以下约定:
x10~x17:8 个参数寄存器,用于传递参数或返回值。x1:1 个返回地址寄存器,用于返回到起始点。
为了完成跳转,RISC-V 汇编语言包含两个跳转-链接指令 (jump-and-link instruction)。
第一个是 jal,用于跳转到某个地址的同时将下一条指令的地址保存到目标寄存器 rd,使用方法是:
jal reg, ProcedureAddress // jump to ProcedureAddress and write return address to register storing the return address
指令中的链接部分表示指向调用点的地址或链接,以允许该过程返回到合适的地址。存储在寄存器 reg,即指令地址寄存器 (instruction address register) 中的这个「链接」称作返回地址 (return address)。返回地址是必需的,因为同一过程可能在程序的不同部分被调用。
由于历史原因,指令地址寄存器也常称作程序计数器 (program counter)。在 RISC-V 中,这一寄存器缩写为 PC,通常是 x1。
第二个是 jalr,用于支持过程的返回,使用方法是:
jalr reg, imm(base_reg) // jump back to saved address and write return address to register storing the return address
目标寄存器 reg 保存返回地址,通常使用 x0 作为目标寄存器,以丢弃返回地址。同时指令跳转回到存储在寄存器 base_reg 中的地址。
总的来说,调用程序,即调用者 (caller) 将参数值放入 x10~x17 中,并使用 jal x1, X 跳转到过程 X,即被调用者 (callee)。被调用者执行计算,将结果放在相同的参数寄存器中,并使用 jalr x0, 0(x1) 将控制返还给调用者。
变量
f到k对应于寄存器x20到x25,寄存器x5的值为 4,编译如下 C 语言代码:switch (k) { case 0: f = i + j; break; case 1: f = g + h; break; case 2: f = g - h; break; case 3: f = i - j; break; }得到的 RISC-V 代码为:
blt x25, x0, Exit // test if k < 0 bge x25, x5, Exit // or k >= 4, go to Exit slli x7, x25, 3 // Temp reg x7 = k * 8 add x7, x7, x6 // x7 = address of JumpTable[k] ld x7, 0(x7) // Temp reg x7 gets JumpTable[k] jalr x1, 0(x7) // jump based on register x7 (entrance) Exit:Jump address table:
x7 = x6 + k * 8,对应L0到L3。Memory 中存放
L0到L3的具体指令:L0: add x20, x24, x25 // k = 0 so f gets i + j jalr x0, 0(x1) // end of this case so go to Exit L1: add x20, x21, x22 // k = 1 so f gets g + h jalr x0, 0(x1) // end of this case so go to Exit L2: sub x20, x24, x25 // k = 2 so f gets g - h jalr x0, 0(x1) // end of this case so go to Exit L3: sub x20, x21, x22 // k = 3 so f gets i - j jalr x0, 0(x1) // end of this case so go to Exit
使用更多的寄存器
假设对于一个过程,编译器需要比 8 个参数寄存器更多的寄存器,且过程完成后调用者所需的所有寄存器都必须恢复到调用该过程之前所存储的值。此时我们就需要将寄存器换出到存储器中。
换出寄存器的理想数据结构是栈 (stack)。栈需要一个指向栈中最新分配地址的指针,以指示下一个过程应该放置置换出寄存器的位置或寄存器旧值的存放位置。在 RISC-V 中,栈指针 (stack pointer) 是寄存器 x2,也记作 sp。栈指针按照每个被保存或回复的寄存器按双字进行调整。
在看具体的例子前,我们也给出 RISC-V 对寄存器的一些约定。RISC-V 软件将 19 个寄存器分为两组:
x5~x7和x28~x31:临时寄存器,在过程调用中不被被调用者(被调用的过程)保存。x8~x9和x18~x27:保存寄存器 (saved register),在过程调用中必须被保存。一旦使用,由被调用者保存并恢复。
变量
g、h、i、j对应于寄存器x10到x13,变量f对应于寄存器x20,编译如下 C 语言代码:long long int leaf_example (long long int g, long long int h, long long int i, long long int j) { long long int f; f = (g + h) - (i + j); return f; }得到的 RISC-V 代码为:
leaf_example: addi sp, sp, -24 // adjust stack to make room for 3 items sd x5, 16(sp) // save register x5 for use afterwards sd x6, 8(sp) // save register x6 for use afterwards sd x20, 0(sp) // save register x20 for use afterwards add x5, x10, x11 // register x5 contains g + h add x6, x12, x13 // register x6 contains i + j sub x20, x5, x6 // f = x5 - x6, which is (g + h) - (i + j) addi x10, x20, 0 // returns f ld x20, 0(sp) // restore register x20 for caller ld x6, 8(sp) // restore register x6 for caller ld x5, 16(sp) // restore register x5 for caller addi sp, sp, 24 // adjust stack to delete 3 items jalr x0, 0(x1)可以看到,总的流程可以分为 4 步:
- 将传入值压入栈中;
- 执行过程并保存返回值;
- 从栈中弹出数据来恢复旧值;
- 跳转返回以结束过程。
嵌套过程
不调用其它过程的过程称作叶子 (leaf) 过程。显然不是所有过程都是叶子过程,于是各过程间会存在嵌套关系。此时就存在潜在的寄存器冲突。
一种解决方法是将其它所有必须保存的寄存器压栈。具体来说:
- 调用者将所有调用后还需要的参数寄存器或临时寄存器压栈
- 被调用者将返回地址寄存器和自身使用的保存寄存器压栈
调整栈指针 sp 以计算压栈寄存器的数量,返回时从存储器中恢复寄存器并重新调整栈指针。
变量
n对应于寄存器x10,编译如下 C 语言代码:long long int fact (long long int n) { if (n < 1) { return 1; } else { return n * fact(n - 1); } }得到的 RISC-V 代码为:
fact: addi sp, sp, -16 // adjust stack for 2 items sd x1, 8(sp) // save the return address sd x10, 0(sp) // save the argument n addi x5, x10, -1 // x5 = n - 1 bge x5, x0, L1 // if (n - 1) >= 0, go to L1 addi x10, x0, 1 // n < 1: return 1 addi sp, sp, 16 // pop 2 items off stack jalr x0, 0(x1) // return to caller L1: addi x10, x10, -1 // n >= 1: arguments gets (n - 1) jal x1, fact // call fact with (n - 1) addi x6, x10, 0 // return from jal: move result of > fact (n - 1) to x6 ld x10, 0(sp) // restore argument n ld x1, 8(sp) // restore the return address addi sp, sp, 16 // adjust stack pointer to pop 2 items mul x10, x10, x6 // return n * fact (n - 1) jalr x0, 0(x1) // return to the caller
下表总结了过程调用中保存的与不保存的对象。

在栈中为新数据分配空间
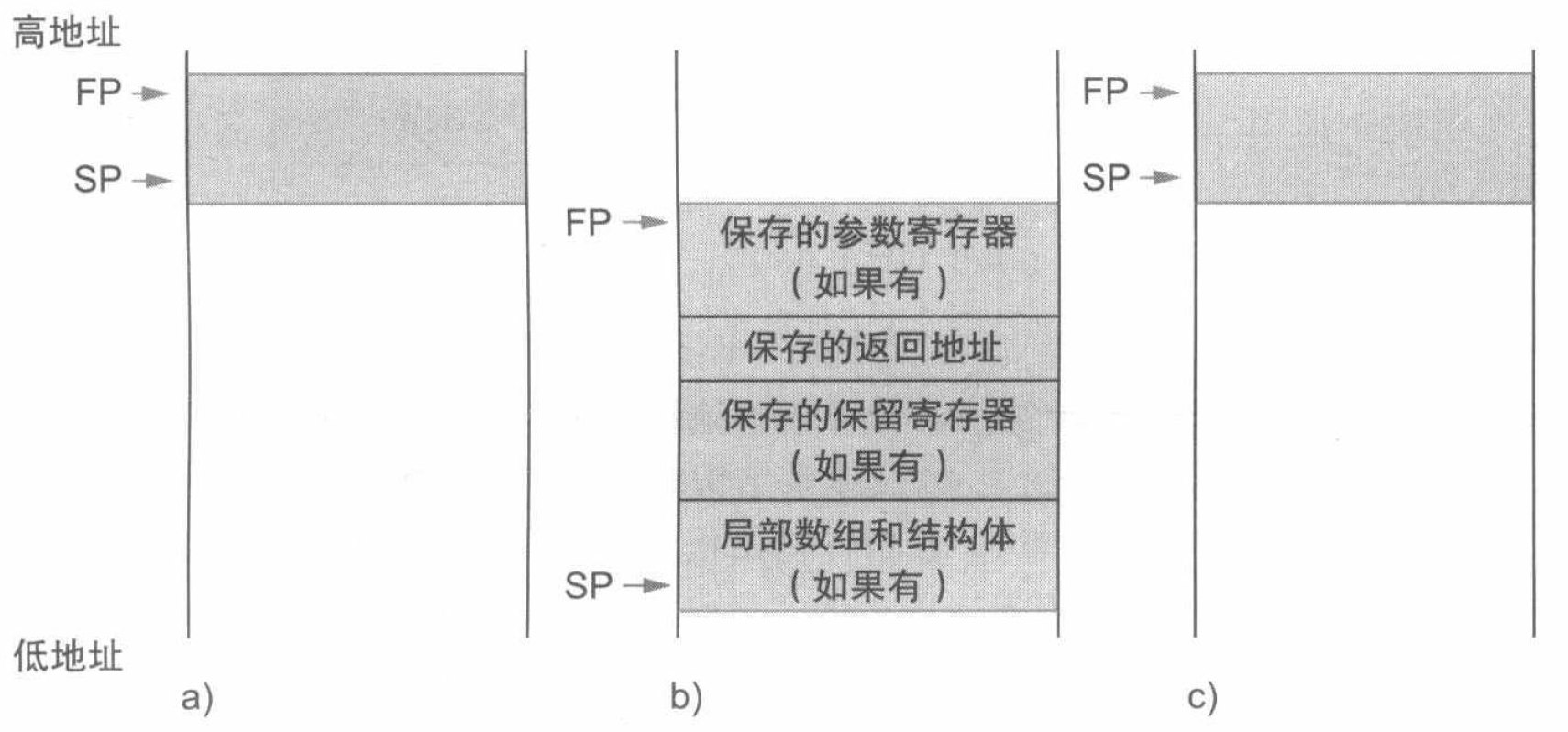
最后一个复杂点在于,栈也用于存储过程的局部变量,但这些变量不适用于寄存器,例如局部数组或结构体。栈中包含过程所保存的寄存器和局部变量的段称作过程帧 (procedure frame) 或活动记录 (activation record)。
一些 RISC-V 编译器使用帧指针 (frame pointer) fp 或寄存器 x8 来指向过程帧的第一个双字。下图展示了过程调用之前、期间和之后时栈的状态。
在堆中为新数据分配空间
一般在操作系统中,栈从用户地址空间的高端开始并向下扩展。低端内存的第一部分是保留的,之后是 RISC-V 机器代码,通常称作代码段 (text segment)。在此之上是静态数据段 (static data segment),用于存放常量和其它静态变量。下图即展示了这一分配结构:

常用堆 (heap) 来存放数组和链表等数据结构,其也放在内存中。
最后,我们总结一下 RISC-V 汇编语言的寄存器约定:
对大立即数的 RISC-V 编址和寻址
RISC-V 指令均保持 32 位长,但有时我们会使用较长的常量。这些大常量需要的特定更多处理方式。
大立即数
RISC-V 指令系统包括指令取立即数高位 (load upper immediate),即 lui,使用方法是:
lui rd, imm
即将一个 20 位立即数 imm 加载到寄存器 rd 的第 31 位到第 12 位,低 12 位则用 0 填充。
将 64 位常量
00000000 00000000 00000000 00000000 00000000 00111101 00000101 00000000加载到寄存器x19的汇编代码是什么?lui x19, 976 // 976 (dec) = 0000 0000 0011 1101 0000 (bin) addi x19, x19, 1280 // 1280 (dec) = 0101 0000 0000 (bin)即先加载 12 到 31 位,再添加低 12 位即可。
但是,我们需要再看一个例子:
将 64 位常量
00000000 00000000 00000000 00000000 00000000 00111101 00001001 00000000加载到寄存器x19的汇编代码是什么?lui x19, 977 // 976 (dec) = 0000 0000 0011 1101 0000 (bin) addi x19, x19, 2304 // 2304 (dec) = 1001 0000 0000 (bin)此时请注意,我们的
lui添加的常数不再是976,而是换成了977。
我们将详细地解释这一差别。两次操作的差别在于,我们第二步 addi 中加的立即数的最高位,第一次是 0,第二次是 1。由于 addi 会将立即数的最高位视作符号位,并对更高位都采用符号位扩展,即将第 12 位更高的位数全部填充为 1。这时为了保证计算结果的正确性,我们选择在 lui 第一步为置高位的常数加 \(1\),这样多出来的这个 \(1\),和 addi 时多出来的 \(11 \cdots 1\) 相加刚好溢出。从而保证了结果的正确性。
分支中的寻址
RISC-V 分支指令中使用的寻址称作绝对寻址,以下是两个例子:
bne x10, x11, 2000 // if x10 != x11, go to location 2000 (dec) = 0111 1101 0000 (bin)
jal x0, 2000 // go to location 2000 (dec) = 0111 1101 0000 (bin)
这种格式可以表示从 \(-4096\) 到 \(4094\) 的分支地址,且只能跳转到其中的偶数地址。但是很显然的,这个地址范围对于当下的程序来说太小了,因此我们将采用一种称作相对寻址的方法。
常用的相对地址这样计算:
即程序计数器(PC)存放着当前指令的地址,我们基于它再距离当前指令的 \(\pm 2^{10}\) 个字的地方建立分支。这种形式的寻址方式称作 PC 相对寻址 (PC-relative addressing)。
这里我们统一解释以下为什么跳转地址只能跳转偶数,以及偏移量是立即数的 2 倍。事实上指令里的立即数存放的是 imm[:1] ,而不存放 imm[0] 并默认 imm[0] 为 0。这显然是出于增大立即数能表示的范围的目的,但同时就造成了上述两个特殊性质。这一点在使用中需要特别注意!
容易知道,无条件跳转指令往往比条件跳转指令能存放更远的地址。因此以下述指令为例:
beq x10, x0, L1
如果 L1 的地址过远,会将条件取反后插入无条件跳转以达成目标。举例来说就是:
bne x10, x0, L2
jal x0, L1
L2:
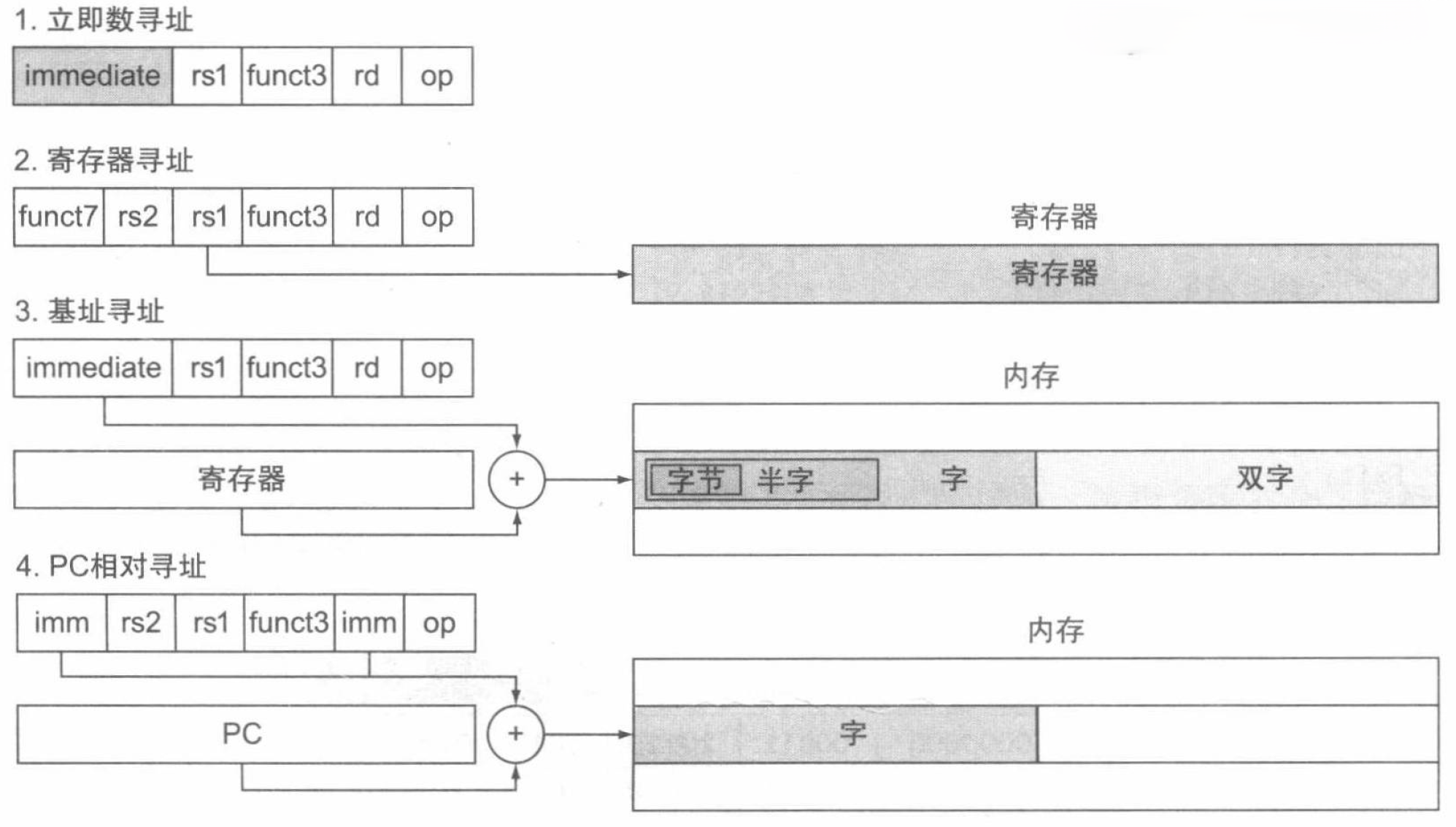
RISC-V 寻址模式总结
多种不同的寻址形式称作寻址模式 (addressing modes)。下图展示了 RISC-V 中的寻址模式:
具体来说:
- 立即数寻址:操作数是指令本身的常量。
- 寄存器寻址:操作数在寄存器中。
- 基址或偏移寻址:操作数于内存中,其地址是寄存器和指令中的常量之和。
- PC 相对寻址:分支地址是 PC 和指令中常量之和。
机器语言译码
下表展示了 RISC-V 机器语言对应的二进制编码:
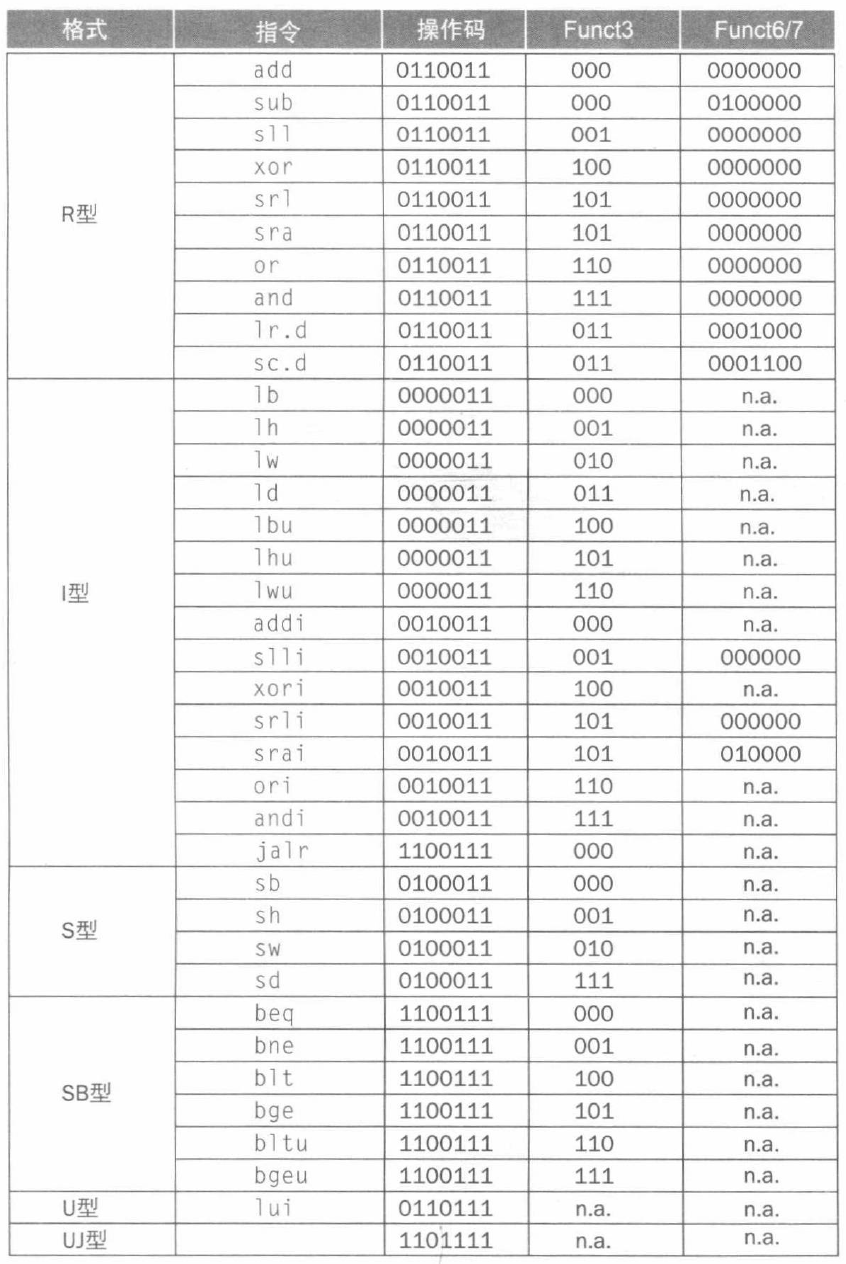
根据这张表,我们即可进行汇编语言和机器码的互译。简要讲述将机器码译为汇编语言的步骤:
- 查看最右边 7 位的
opcode,确定指令类型。 - 查看
funct7和funct3,确定具体指令。 - 查看剩余字段,并对应该类型指令的格式解释指令。
对于最后一步,我们要查阅下表,即每种类别的指令对应的字段分布。
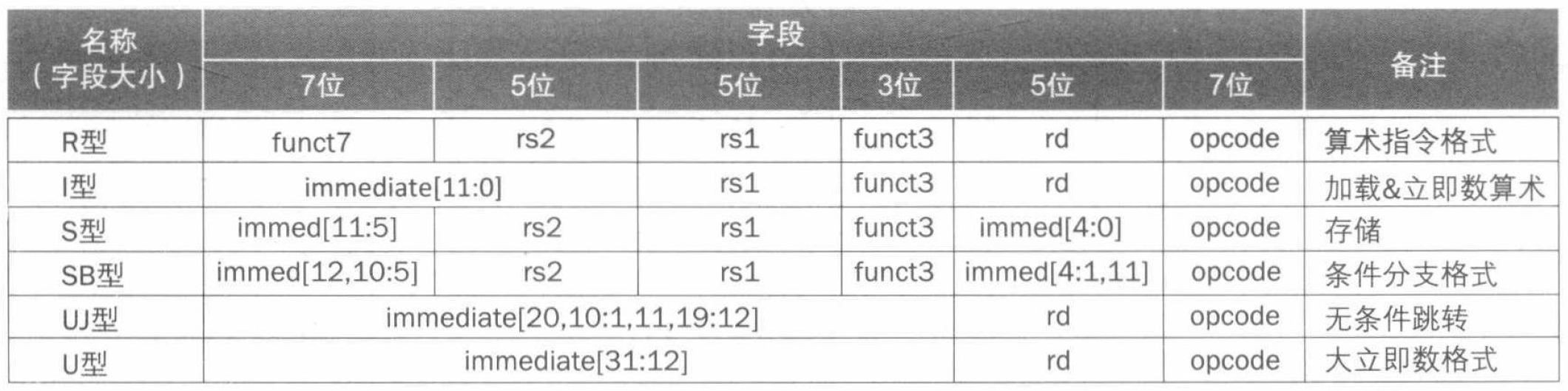
同步
鉴于课本上这一章的介绍过于细碎繁琐,同时并非考察重点,为了保证内容的正确性和易读性,这里引用 NoughtQ 的笔记本中的介绍。
翻译并启动程序
鉴于课本上这一章的介绍过于细碎繁琐,同时并非考察重点,为了保证内容的正确性和易读性,这里引用 NoughtQ 的笔记本中的介绍。
以 C 排序程序为例的汇总整理
这里我们将展示一些完整的 C 语言函数和对应的汇编语言代码。
swap 过程
void swap (long long int v[], size_t k) {
long long int temp;
temp = v[k];
v[k] = v[k + 1];
v[k + 1] = temp;
}
RISC-V 的参数传递默认使用寄存器 x10 到 x17。由于 swap 只有两个参数 v 和 k,因此将其在 x10 和 x11 中保存。唯一的一个变量 temp 用临时寄存器 x5 来保存。
接下来我们一步步实现汇编代码。首先,RISC-V 的内存地址是字节寻址,因此双字实际上相差 \(8\) 个字节。所以在将索引 \(k\) 与地址相加前,需要将其值乘以 \(8\)。故第一步如下:
slli x6, x11, 3 // reg x6 = k * 8
add x6, x10, x6 // reg x6 = v + (k * 8)
现在用 x6 加载 v[k],用 x6 + 8 加载 v[k + 1],请注意,这一步已经隐含实现了 temp = v[k]。
ld x5, 0(x6) // reg x5 (temp) = v[k]
ld x7, 8(x6) // reg x7 = v[k + 1]
接下来将 x5 和 x7 中的值存储到交换的地址。
sd x7, 0(x6) // v[k] = reg x7
sd x5, 8(x6) // v[k + 1] = reg x5 (temp)
swap:
slli x6, x11, 3 // reg x6 = k * 8
add x6, x10, x6 // reg x6 = v + (k * 8)
ld x5, 0(x6) // reg x5 (temp) = v[k]
ld x7, 8(x6) // reg x7 = v[k + 1]
sd x7, 0(x6) // v[k] = reg x7
sd x5, 8(x6) // v[k + 1] = reg x5 (temp)
jalr x0, 0(x1) // return to calling routine
sort 过程
void sort (long long int v[], size_t int n) {
size_t i, j;
for (i = 0; i < n; i += 1) {
for (j = i - 1; j >= 0 && v[j] > v[j + 1]; j -= 1) {
swap(v, j);
}
}
}
过程 sort 的 v 和 n 两个参数保存在参数寄存器 x10 和 x11 中,同时我们将寄存器 x19 分配给 i,x20 分配给 j。
过程体由两个嵌套的 for 循环和一个包含参数的 swap 调用组成。我们从外向内展开代码。
第一个翻译步骤是第一个 for 循环:
for (i = 0; i < n; i += 1) {
}
这包括三部分:初始化、循环判断、循环增值。于是第一个 for 循环的代码框架是:
li x19, 0
for1tst:
bge x19, x11, exit1 // go to exit1 if x19 >= x11 (i >= n)
...
(body of first for loop)
...
addi x19, x19, 1 // x += 1
j for1tst // branch to test of outer loop
exit1:
第二个翻译步骤即第二个 for 循环:
for (j = i - 1; j >= 0 && v[j] > v[j + 1]; j -= 1) {
}
类似地,其对应的代码框架是:
addi x20, x19, -1 // j = i - 1
for2tst:
blt x20, x0, exit2 // fo to exit2 if x20 < 0 (j < 0)
slli x5, x20, 3 // reg x5 = j * 8
add x5, x10, x5 // reg x5 = v + (j * 8)
ld x6, 0(x5) // reg x6 = v[j]
ld x7, 8(x5) // reg x7 = v[j + 1]
ble x6, x7, exit2 // go to exit2 if x6 <= x7
...
(body of second for loop)
...
addi x20, x20, -1 // j -= 1
j for2tst // branch to test of inner loop
exit2:
下一步就是翻译循环内的操作,即
swap(v, j);
这对应如下的汇编操作:
mv x10, x21 // first swap parameter is v
mx x11, x20 // second swap parameter is j
jal x1, swap
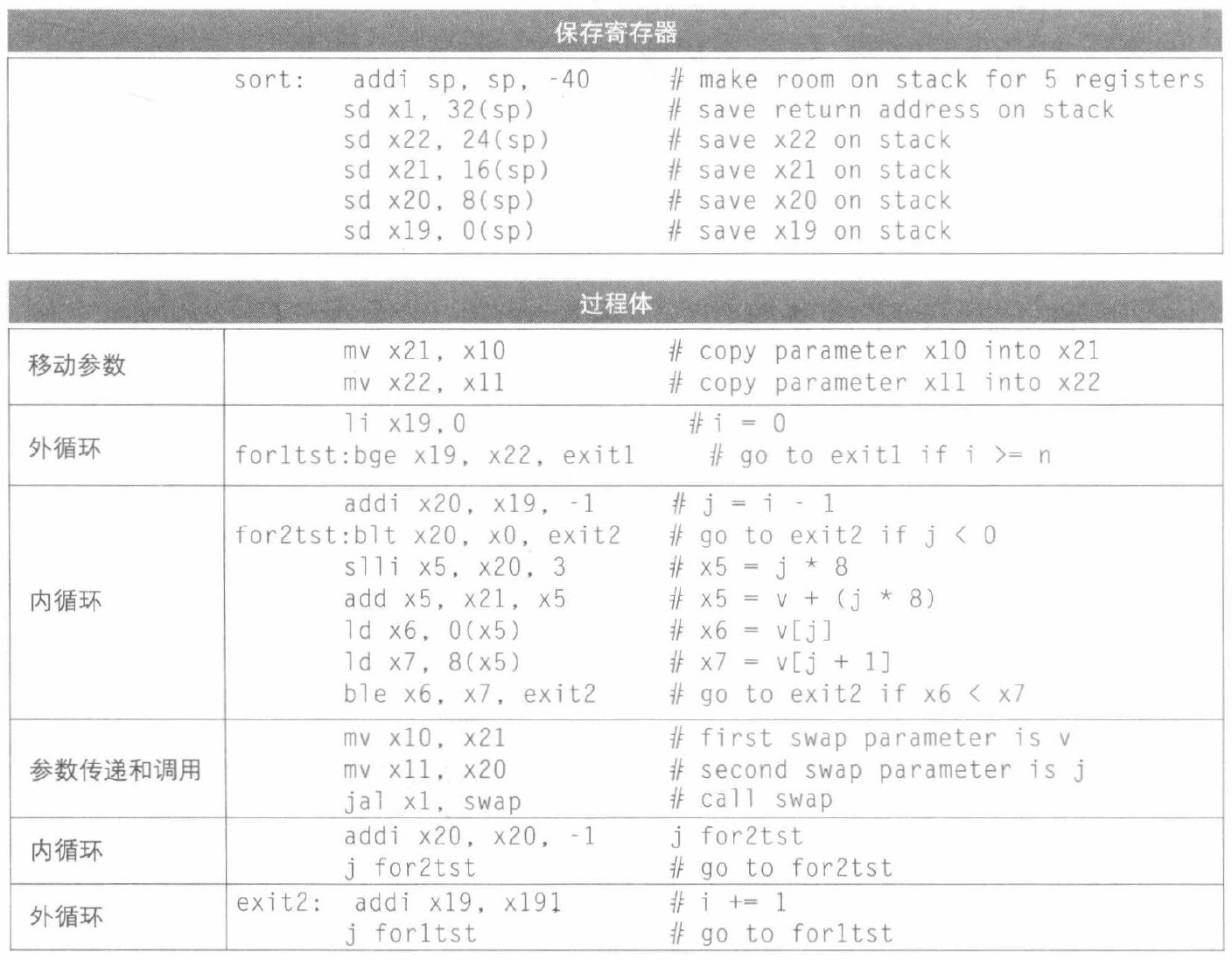
最后,还要完成寄存器的保存和恢复。其过程头如下:
addi sp, sp, -40 // make room on stack for 5 regs
sd x1, 32(sp) // save x1 on stack
sd x22, 24(sp) // save x22 on stack
sd x21, 16(sp) // save x21 on stack
sd x20, 8(sp) // save x20 on stack
sd x19, 0(sp) // save x19 on stack
最后,我们呈现完整的 sort 过程:

数组与指针
在 C 语言中,使用数组和指针往往是两种不同的代码实现方式,而实际上两者对应的汇编代码也不同。
我们先给出两种不同实现对应的 C 语言代码:
void clear1 (long long int array[], size_t int size) {
size_t i;
for (i = 0; i < size; i += 1) {
array[i] = 0;
}
}
void clear2 (long long int *array, size_t int size) {
long long int *p;
for (p = &array[0]; p < &array[size]; p = p + 1) {
*p = 0;
}
}
接下来,我们将展示并比较两者汇编代码间的差异。
数组实现
li x5 = 0 // i = 0
loop1:
slli x6, x5, 3 // x6 = i * 8
add x7, x10, x6 // x7 = address of array[i]
sd x0, 0(x7) // array[i] = 0
addi x5, x5, 1 // i = i + 1
blt x5, x11, loop1 // if (i < size) go to loop1
指针实现
mv x5, x10 // p = address of array[0]
loop2:
sd x0, 0(x5) // Memory[p] = 0
addi x5, x5, 8 // p = p + 8
slli x6, x11, 3 // x6 = size * 8
add x7, x10, x6 // x7 = address of array[size]
bltu x5, x7, loop2 // if (p < &array[size]) go to loop2