第四章 - 处理器
约 11261 个字 40 行代码 预计阅读时间 38 分钟
本章将概括地介绍实现处理器所要用到的原理和技术。首先从一个高度抽象和简化的概述开始,之后以此为基础为 RISC-V 指令系统构建数据通路,并设计一种简单的、能够实现指令系统的处理器。之后,我们将探讨更接近实际情况的流水线 RISC-V。
一种基本的 RISC-V 实现
我们将实现 RISC-V 的一个核心子集:
- 存储器访问指令 load doubleword (
ld) 和 store doubleword (sd) - 算术逻辑指令
add、sub、and和or - 条件分支指令 branch if equal (
beq)
这个子集说明了简历数据通路和设计控制的关键原理,其余指令的实现也与这个子集类似。
对于这三类指令,其实现每条指令的前几个步骤是类似的:
- 程序计数器(PC)发送到指令所在的存储单元,并从中取出指令。
- 根据指令的某些字段选择要读取的 1 个或 2 个寄存器。
- 使用算术逻辑单元(ALU):存储器访问指令用 ALU 进行地址计算,算术逻辑指令用 ALU 执行运算,条件分支指令用 ALU 进行比较。
但在经过 ALU 后,完成各类指令所需的操作就不同了。存储器访问指令需要访问存储器以读取数据或存储数据,算术逻辑指令或载入指令需要将来自 ALU 或存储器的数据写回寄存器,条件分支指令需要很具比较结果更改下一条指令的地址(否则下一条指令的地址通过 PC 加 \(4\) 来获得)。
在这个过程中,许多地方会存在两个来自不同源的数据流向同一个单元。此时就涉及到数据的选择,我们使用多选器 (multiplexor),或称数据选择器 (data selector) 来完成。此外,一些功能单元的控制依赖于当前执行的指令类型。因此我们还需要引入控制单元 (functional unit) 来确定如何设置控制线。
基于以上分析,我们可以得到这样的一个抽象的实现图:
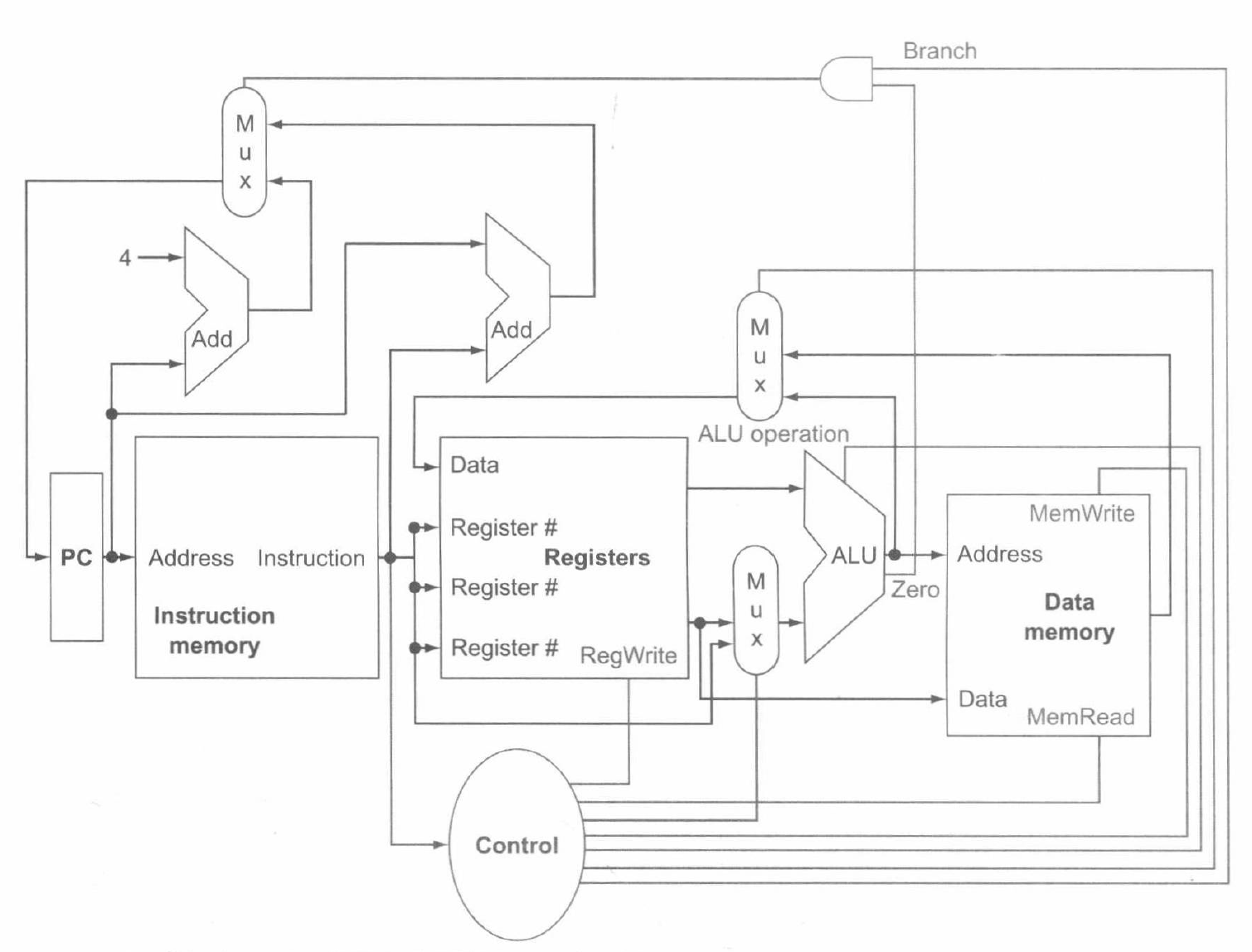
在后续内容中,我们将基于这个实现图继续改进并补充细节,并通过添加时序控制使得处理器可以有序运行指令。
逻辑设计的一般方法
RISC-V 实现中的数据通路包含两种不同类型的逻辑单元:处理数据值的单元和存储状态的单元。处理数据值的单元是组合逻辑 (combinational logic),它们的输出仅依赖于当前输入。设计中的其它单元不是组合逻辑,而是包含状态 (state) 的。如果一个单元有内部存储功能,它就包含状态,称其为状态单元 (state elements)。这些逻辑部件也被称作时序 (sequential) 的,因为其输出取决于输入和内部状态。
时钟同步方法
时钟同步方法 (clocking methodology) 规定了信号可以读出和写入的时间。为简单起见,假定我们采用边沿触发的时钟 (edge-triggered clocking),即存储在时序逻辑单元中的所有值仅在时钟边沿更新。如果状态单元在每个有效时钟边沿都进行写入,则可忽略写控制信号 (control signal)。更进一步地,我们规定仅在时钟上升沿写入。
我们将用术语有效 (asserted) 表示信号为逻辑高,用使有效 (assert) 表示信号应为逻辑高,用无效 (deasserted) 或使无效 (deassert) 表示信号为逻辑低。
Note
这样规定是因为在进行硬件实现时,数字 \(1\) 有时表示逻辑高,又是表示逻辑低。
建立数据通路
设计数据通路的合理方法是,先分析每类 RISC-V 指令需要哪些主要执行单元。本节首先讨论每条指令需要哪些数据通路单元 (datapath element),然后逐渐降低抽象的层次。在设计数据通路单元的同时,也会设计它们的控制信号。
各指令所需的数据通路单元
下图是三个核心的单元:
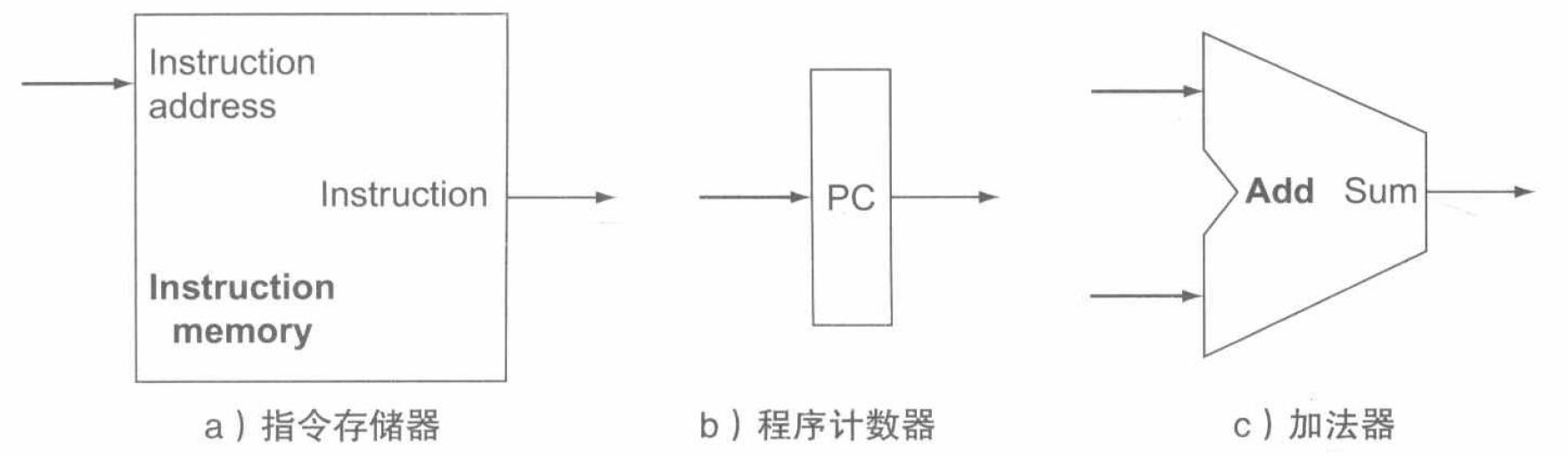
首先是存储单元,用于存储程序的指令,并根据给定地址提供指令。然后是程序计数器(PC),用于保存当前指令的地址。最后还需要一个加法器来增加 PC 的值以获得下一条指令的地址,在实际情况中,这一单元通常使用 ALU,并将控制信号常设为加法来实现。
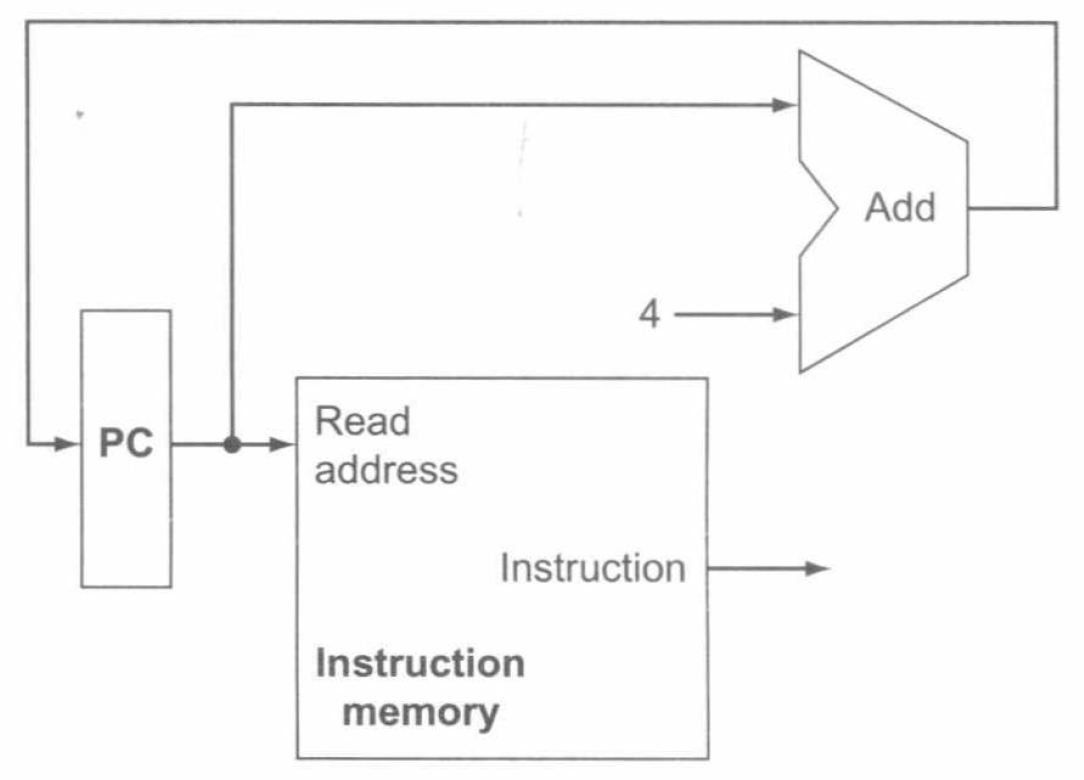
要执行任意一条指令,首先要从存储器中取出指令。为准备执行下一条指令,必须增加程序计数器的值,使其指向下一条指令。这一操作的数据通路如下图:
现在考虑 R 型指令或算术逻辑指令。这类指令读两个寄存器,对它们的内容执行 ALU 操作,再将结果写回寄存器。这些指令包括 add、sub、and 和 or 指令。
处理器的 32 个通用寄存器位于结构寄存器堆 (register file) 中。寄存器堆是寄存器的集合,其中的寄存器可以通过指定相应的寄存器号来进行读写。寄存器堆包含了计算机的寄存器状态。另外,还需要一个 ALU 对从寄存器读出的值进行运算。
由于 R 型指令有 3 个寄存器操作数,每条指令需要从寄存器堆中读出两个数据字,再写入一个数据字。为读出一个数据字,需要一个输入指定要读的存储器号,以及一个从寄存器堆读出的输出。为写入一个数据字,寄存器堆需要两个输入,一个输入指定要写的寄存器号,另一个提供要写入寄存器的数据。其对应的硬件单元如下图:
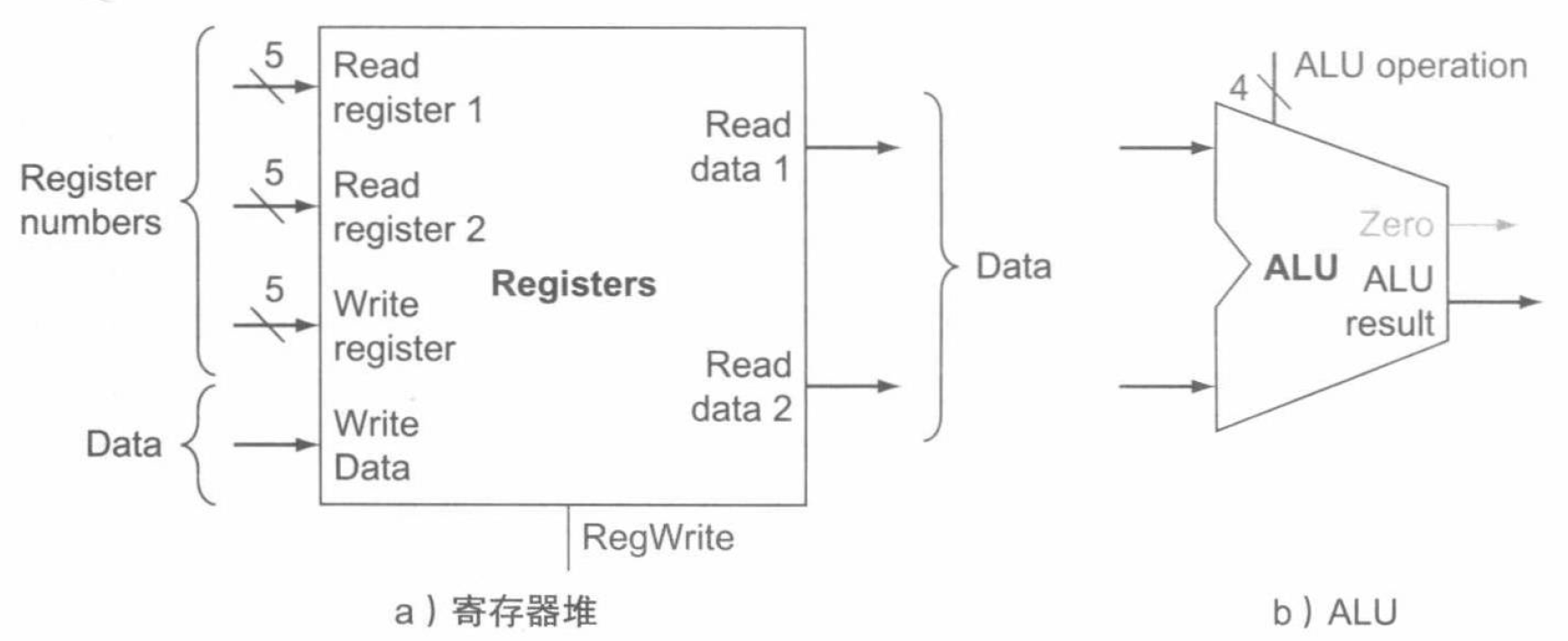
下面考虑 RISC-V 的存取指令,其一般形式为 ld x1, offset(x2) 和 sd x1, offset(x2)。这类指令通过将基址寄存器 x2 与指令中包含的 12 位有符号偏移量相加,得到存储器地址。对于存储指令,从寄存器 x1 中读出要存储的数据;如果是载入指令,那么从存储器中读出的数据要写入指定的寄存器 x1 中。
因此为实现存取指令,除了前述的寄存器堆和 ALU 外,还需要一个单元将指令中的 12 位偏移量符号扩展 (sign-extend) 为 64 位有符号数,以及一个执行读写操作的数据存储单元。数据存储单元在存储指令时被写入,所以它有读写控制信号、地址输入和写入存储器的数据输入。下图给出了这两个单元:
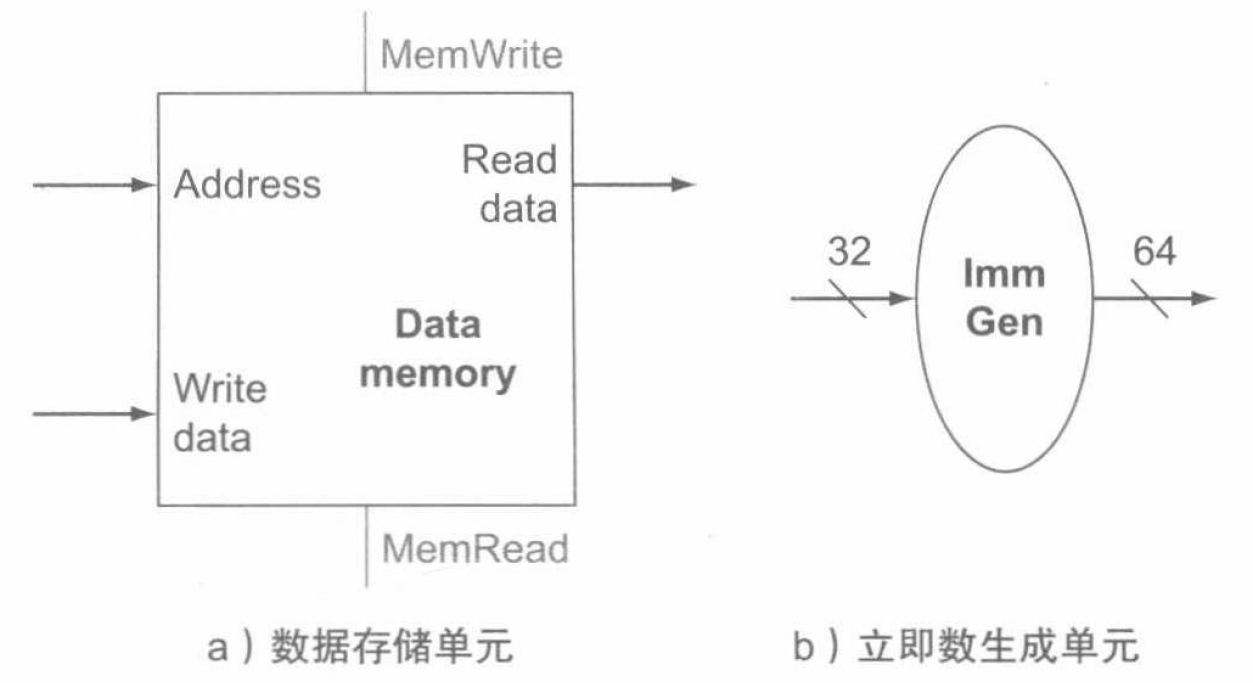
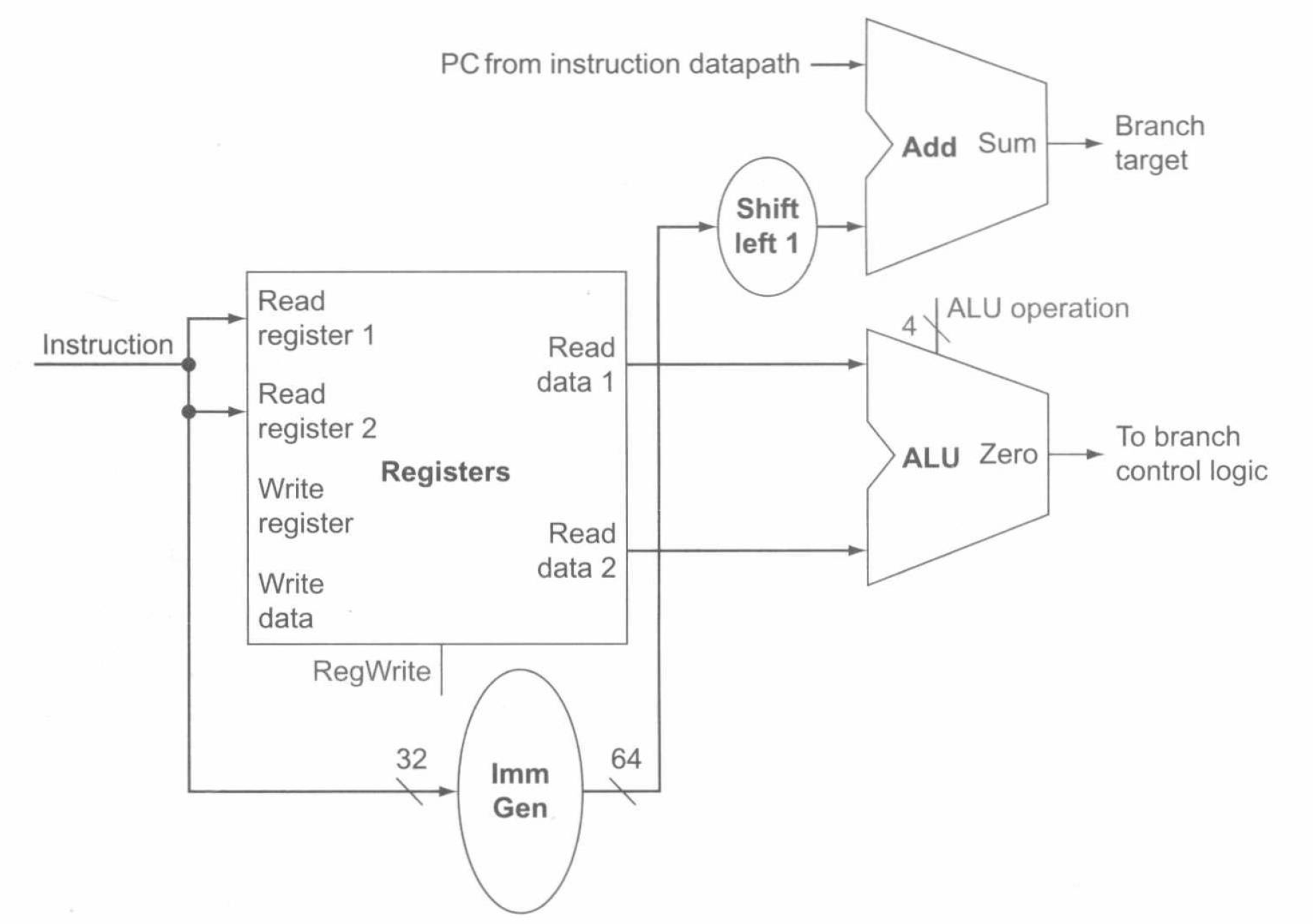
beq 指令有 3 个操作数,其中两个寄存器用于比较是否相等,另一个是 12 位偏移量,用于计算相对于分支指令所在地址的分支目标地址 (branch target address)。其指令格式是 beq x1, x2, offset。为实现 beq 指令,需将 PC 值与符号扩展后的指令偏移量相加以得到分支目标地址。
Note
这里我们再次提醒,基于第二章中分支指令的定义,有 2 个必须注意的细节:
- 指令系统体系结构规定了计算分支目标地址的基址是分支指令所在地址。
- 指令系统体系结构还说明了计算分支目标地址时,将偏移量左移 \(1\) 位以表示半字为单位的偏移量,这样偏移量的有效范围就扩大到 \(2\) 倍。
在计算分支目标地址的同时,必须确定是顺序执行下一条指令,还是执行分支目标地址处的指令。当分支条件为真时,分支目标地址成为新的 PC,我们就称分支发生 (branch is taken)。如果条件不成立,如果条件不成立,自增后的 PC 成为新的 PC,此时就称分支未发生 (branch is not taken)。
因此,分支指令的数据通路需要执行两个操作:计算分支目标地址和检测分支条件。下图即为分支指令的数据通路:
建立一个简单的数据通路
我们已经分别讨论了几类指令需要的数据通路单元,现在可将它们组合成一个完整的数据通路并添加控制信号以完成实现。
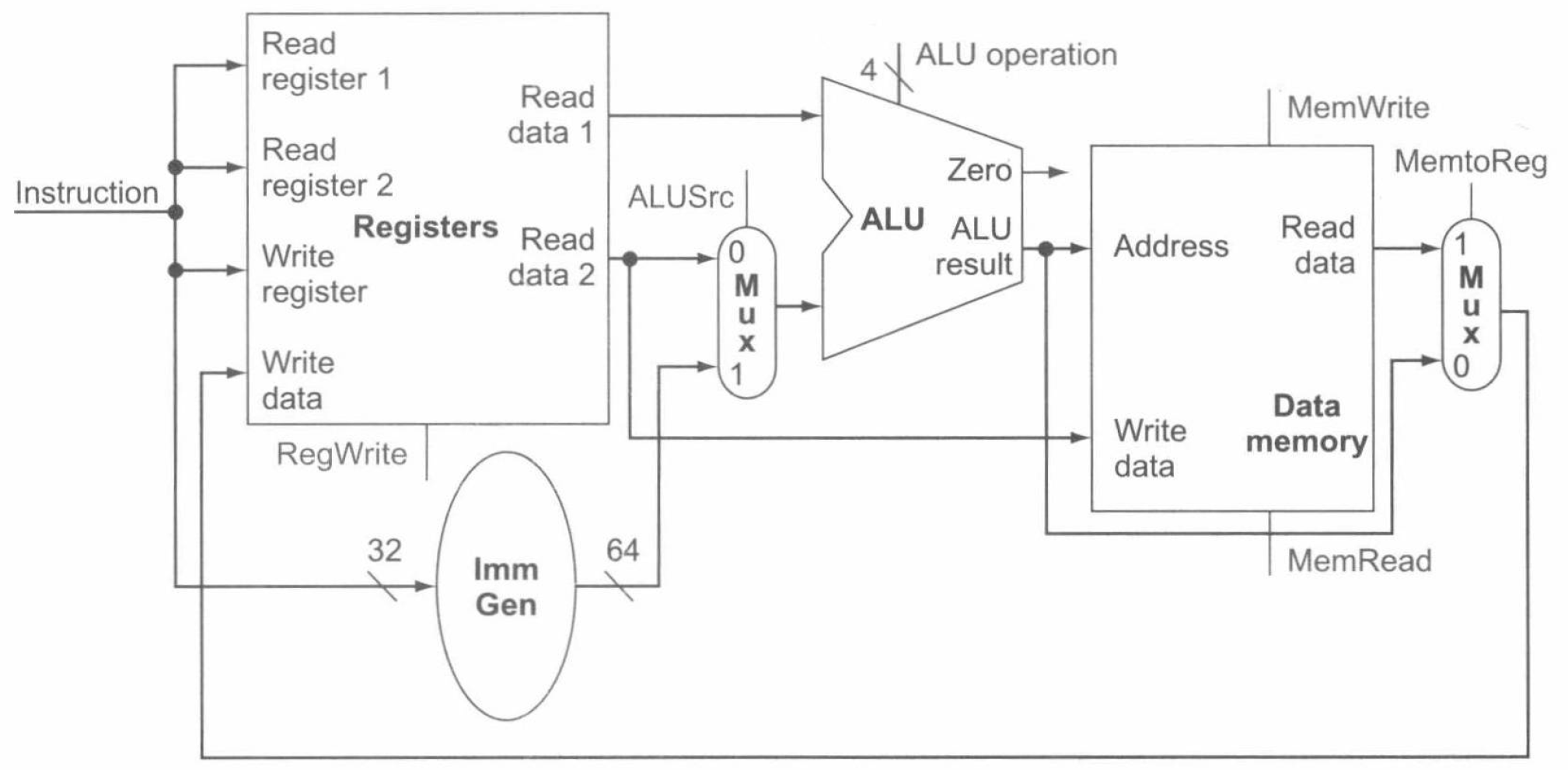
这个最简单的数据通路在每个时钟周期执行一条指令。这意味着每条指令在执行过程中的任何数据通路单元都只能使用一次,如果需要多次使用某数据通路单元,则要将其复制多份。因此,需要一个指令存储器和一个与之分开的数据存储器。尽管还有一些功能单元需要多份,但很多功能单元可以在不同的指令流动中被共享。
为在两个不同类指令之间共享数据通路单元,需要允许一个单元有多个输入,我们用多路选择器和控制信号在多个输入中进行选择。
于是,我们可以构造存储类指令和 R 型指令的数据通路,如下图:
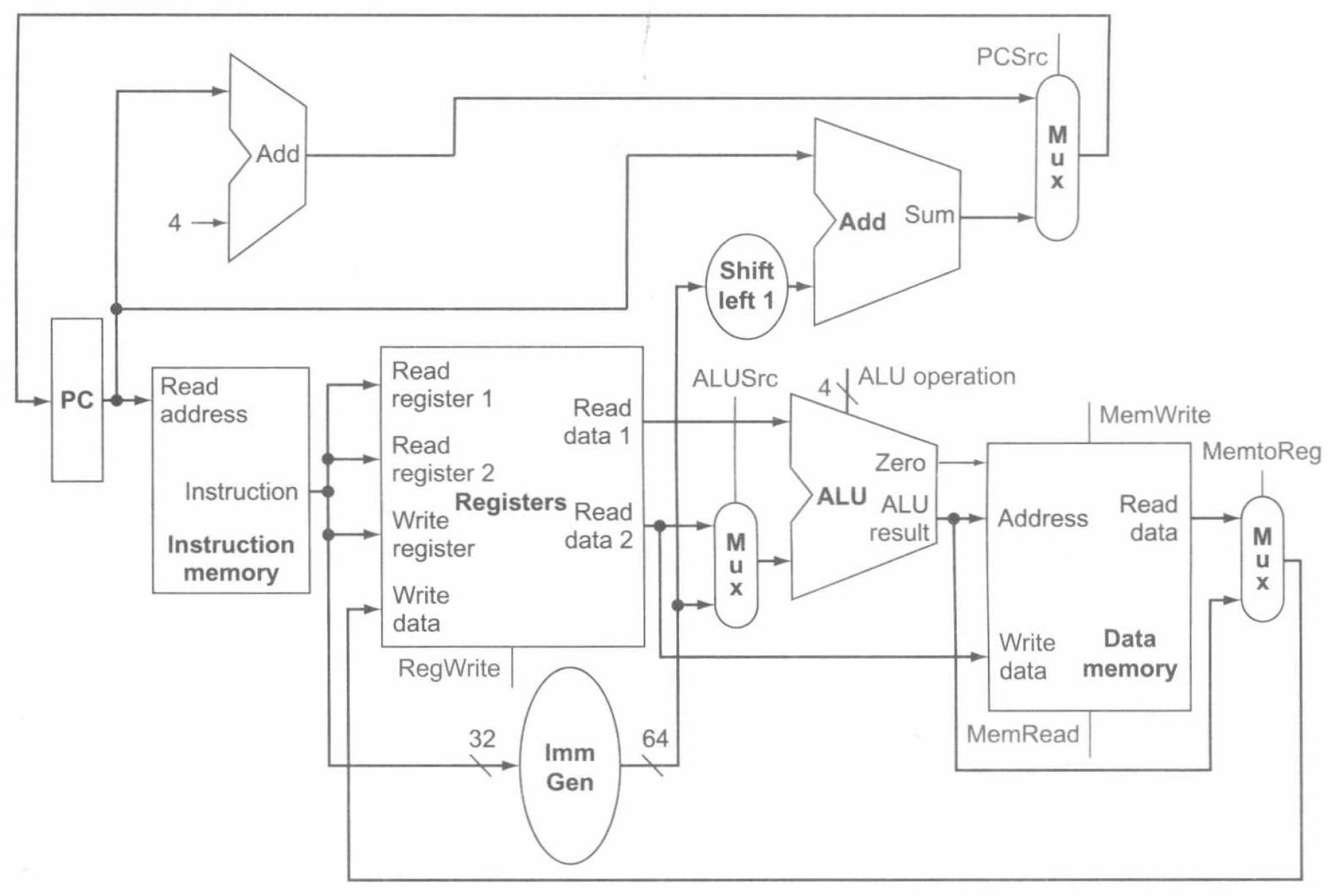
最后,我们将前述的取指令数据通路、R 型指令和存储类指令数据通路、分支指令数据通路合并,就可以得到 RISC-V 指令系统核心集的一个简单数据通路,如下图:
一个简单的实现方案
现在我们已经有了这个简单处理器的数据通路,我们将基于此并增加一个简单的控制单元来实现。
ALU 控制
ALU 的控制是容易的,我们先明确其所有的控制信号:
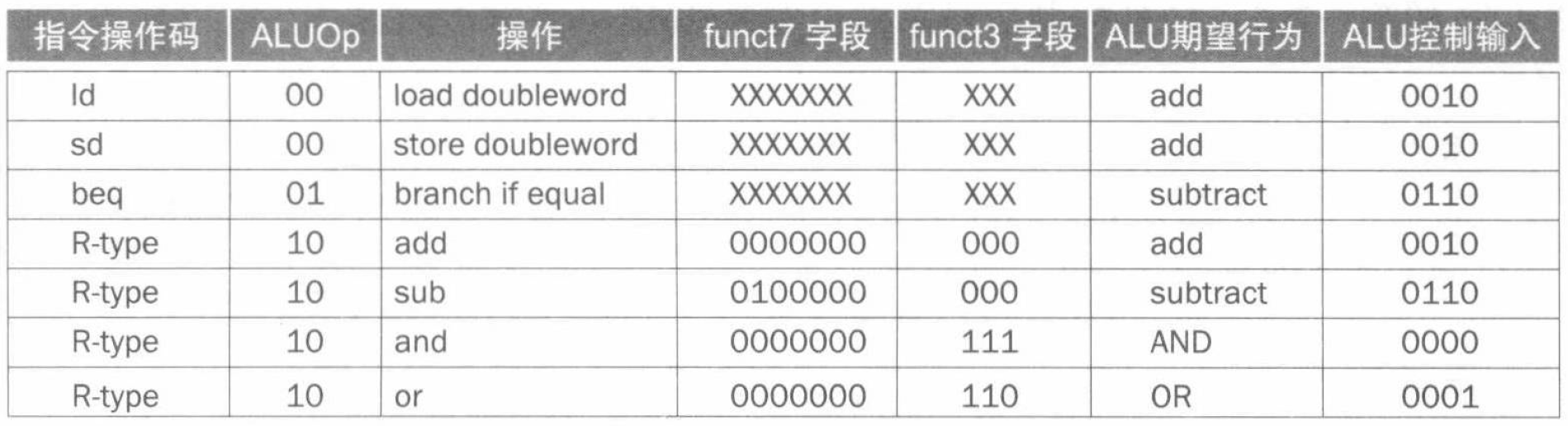
据此,我们可以采用多级译码的方式,得到控制信号的真值表:
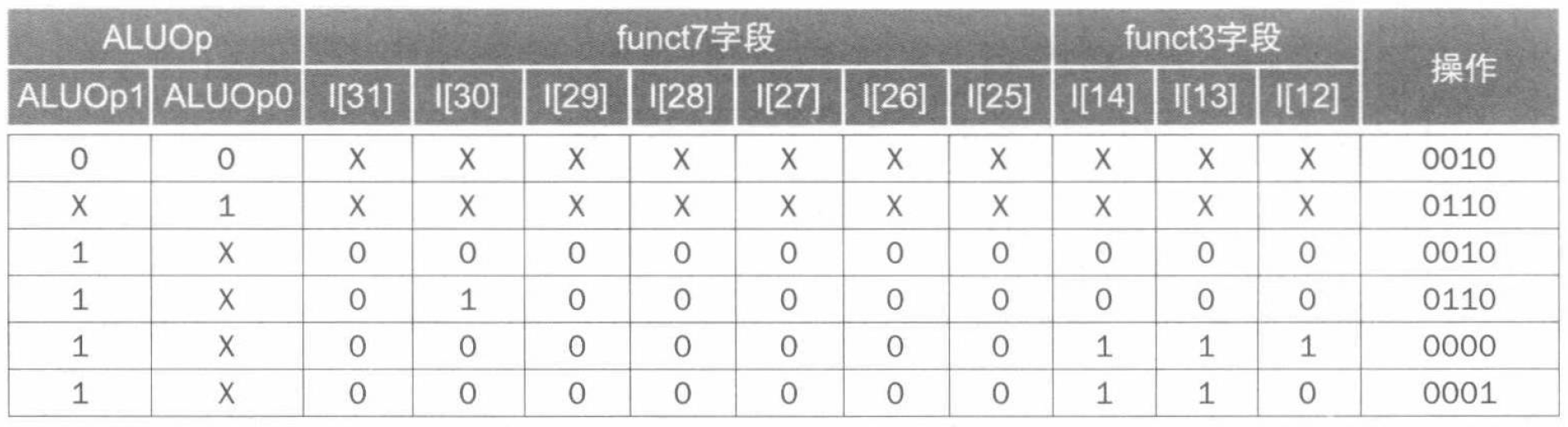
设计主控制单元
现在我们考虑控制的其他部分。对于主控制单元,其需要处理不同的指令,因此要能够有效「解读」指令。所以首先,我们先来回顾四类指令的格式:
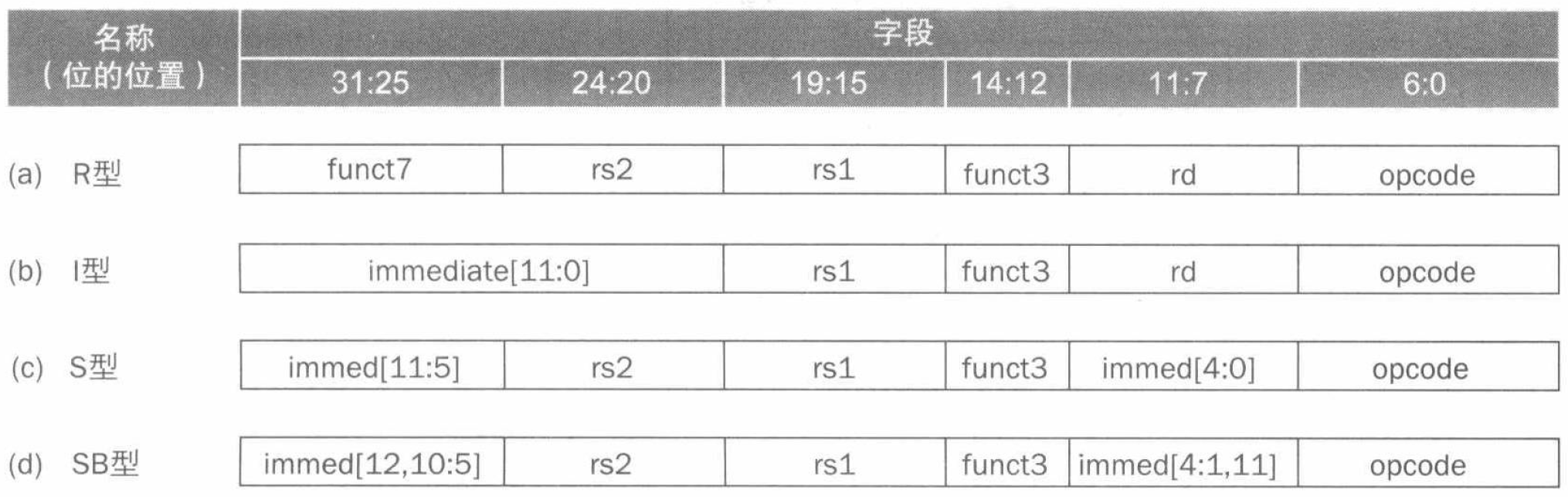
经过一些整理,我们可以引入 6 个控制信号:

设置这些控制信号的对应的真值表如下:

于是,在我们引入了这些控制信号后,就可以得到带有控制单元的简单数据通路:
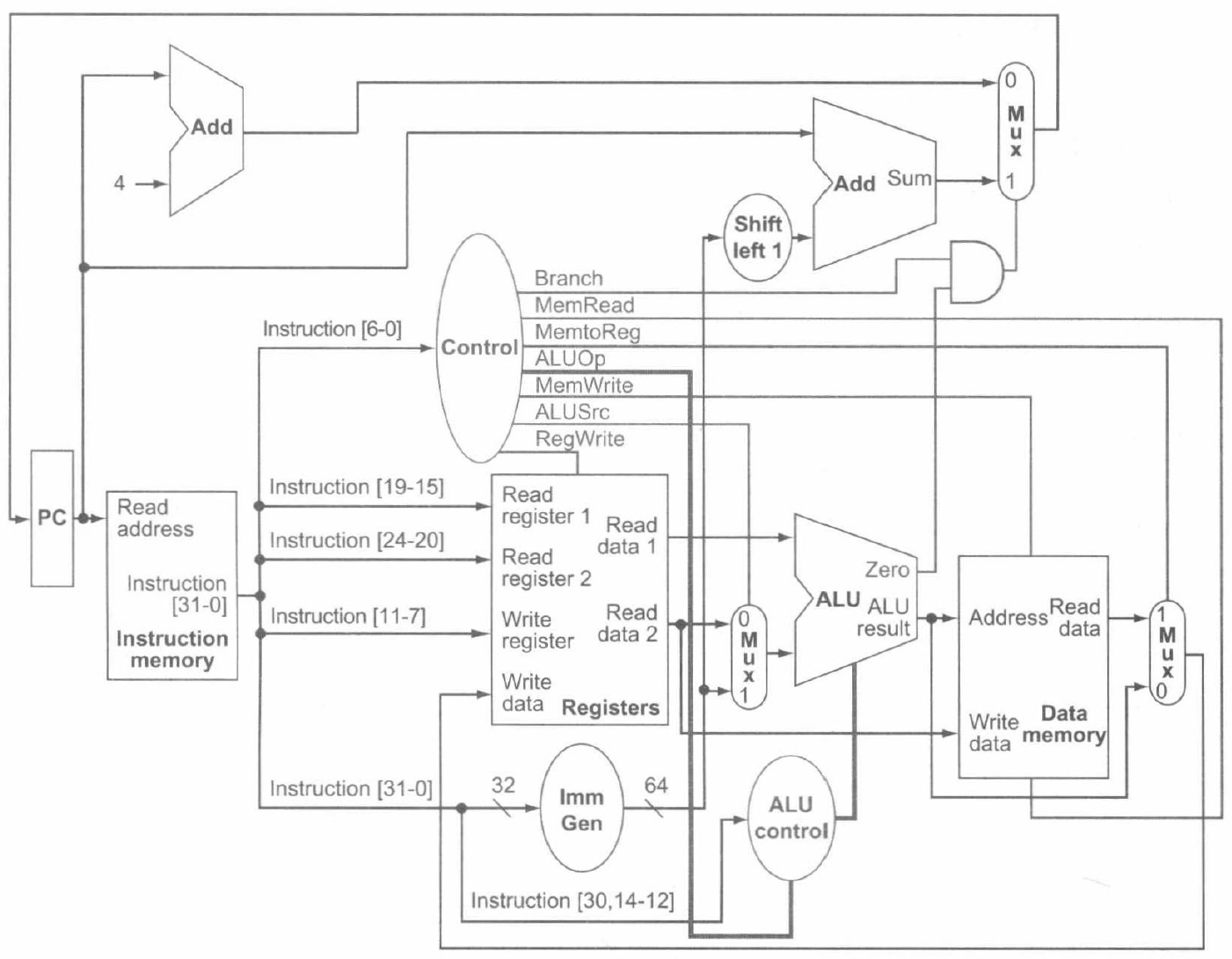
数据通路操作
根据前述的数据通路,我们可以设计控制单元的逻辑。但在此之前,我们可以先明确,各类指令是如何使用数据通路的。
R 型指令的执行可以分为 4 个步骤:
- 取出指令,PC 自增。
- 从寄存器堆读出两个寄存器
x2和x3,同时主控制单元在此步骤计算控制信号。 - 根据部分操作码确定 ALU 的功能,对从寄存器堆读出的数据进行操作。
- 将 ALU 的结果写入寄存器堆中的目标寄存器
x1。
load 指令的执行可以分为 5 个步骤:
- 从指令存储器中取出指令,PC 自增。
- 从寄存器堆读出寄存器
x2的值。 - ALU 将从寄存器堆中读出的值和符号扩展后的指令中的 12 位(偏移量)相加。
- 将 ALU 的结果用作数据存储器的地址。
- 将从存储器读出的数据写入寄存器堆
x1。
branch-if-equal 指令的执行可以分为 4 个步骤:
- 从指令存储器中取出指令,PC 自增。
- 从寄存器堆中读出两个寄存器
x1和x2。 - ALU 将从寄存器堆读出的两数相减。PC 与左移一位、符号扩展的指令中的 12 位(偏移量)相加,结果是分支目标地址。
- ALU 的零输出决定将哪个加法器的结果写入 PC。
控制的结束
我们已经了解了指令如何按步骤操作,现在继续讨论控制单元的实现。控制单元的功能可以根据控制信号精确定义,其输出是控制线,输入是操作码。因此,可以根据操作码的二进制编码为每个输出建立一个真值表,如下:
为什么现在不使用单周期实现
截至目前,我们已经实现了一个单周期的 RISC-V 核心集处理器。因此在进入后文对流水线处理器的探讨前,我们来简单讨论一下单周期处理器的一些问题。
尽管单周期设计可以正确工作,但是在现代设计中不采取这种方式,因为它的效率太低。究其原因,是在单周期设计中时钟周期对于每条指令必须等长。这样,处理器中的最长路径决定了时钟周期。这样即使 CPI 为 \(1\),但单个时钟周期太长,实现的整体性能可能很差。
Note
在多数时候,这条最长路径很可能是一条 load 指令,它连续地使用 5 个功能单元:指令存储器、寄存器堆、ALU、数据存储器和寄存器堆。
使用单周期设计的代价是显著的,但对于小指令集而言,或许是可以接受的。历史上,早期具有简单指令集的计算机确实采用这种实现方式。但是,如果要实现浮点单元或更复杂的指令集,单周期设计根本无法正常工作。
流水线概述
面向流水线的指令系统
流水线 (pipelining) 是一种能使多条指令重叠执行的实现技术。流水线的概念是朴素的,其核心在于,流水线中每个步骤的时间并没有缩短,但流水线通过并行地执行各个步骤,提高了系统的吞吐率 (throughput),从而能够在单位时间内完成更多的工作。
这一原则同样可以用于处理器,即采用流水线方式执行指令。RISC-V 指令执行通常包含 5 个步骤:
- 取指(IF):从存储器中取出指令。
- 译码(ID):读寄存器并译码指令。
- 执行(EX):执行操作或计算地址。
- 访存(MEM):访问数据存储器中的操作数(如有必要)。
- 写回(WB):将结果写入寄存器(如有必要)。
因此,接下来要探讨的 RISC-V 流水线有 5 个阶段。为了使讨论具体化,我们先建立一个流水线。之后我们考虑的是这 7 条指令:ld、sd、add、sub、and、or、beq。
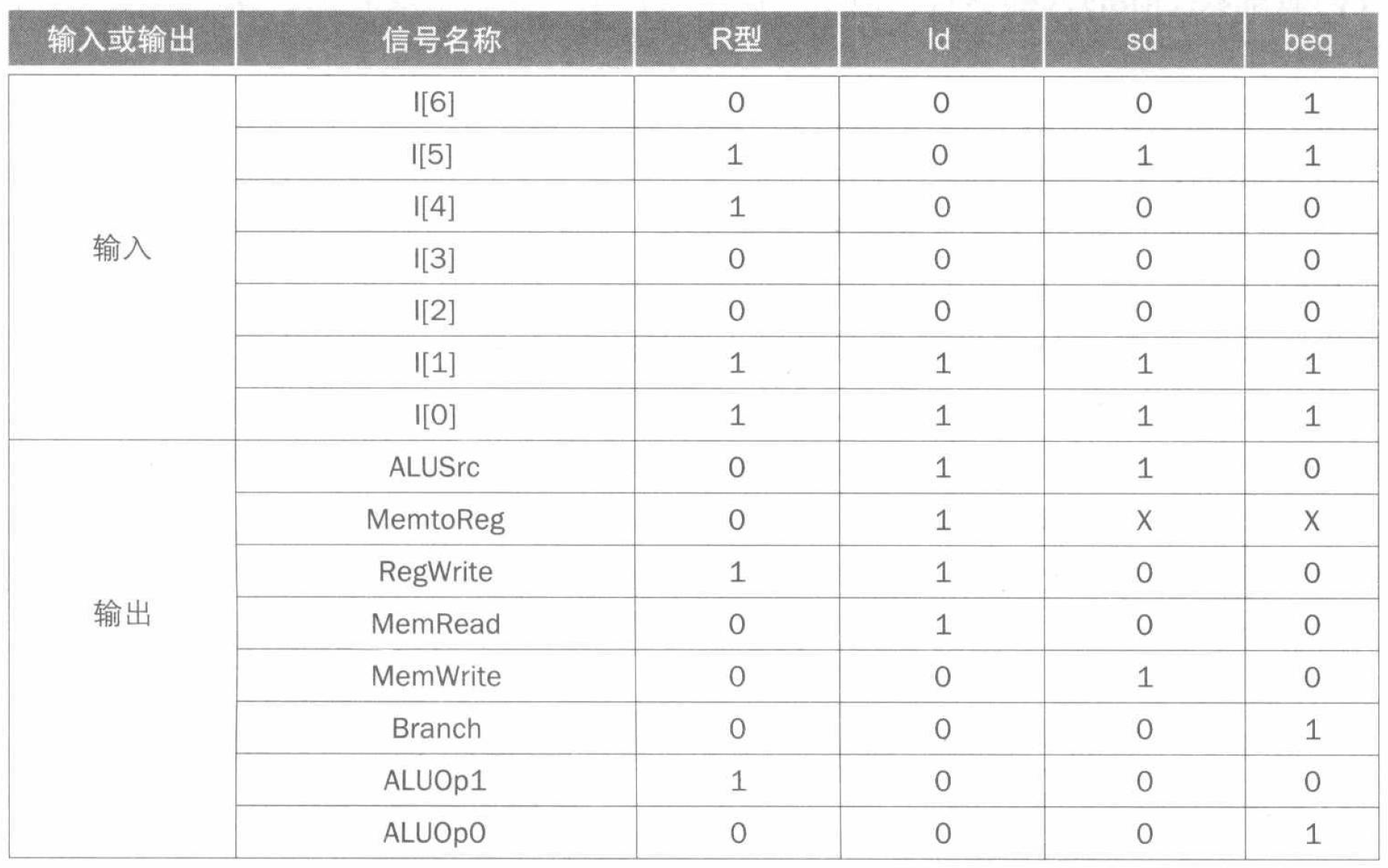
我们先来给出这些指令在各功能单元的处理时间:
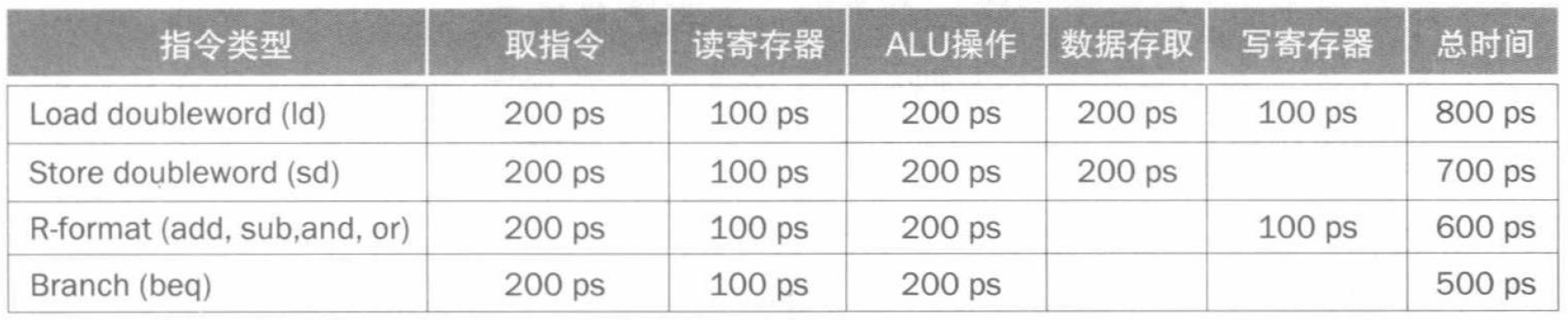
基于这些数据,我们先给出一个执行指令的示例,以直观地感受非流水线和流水线执行的区别:
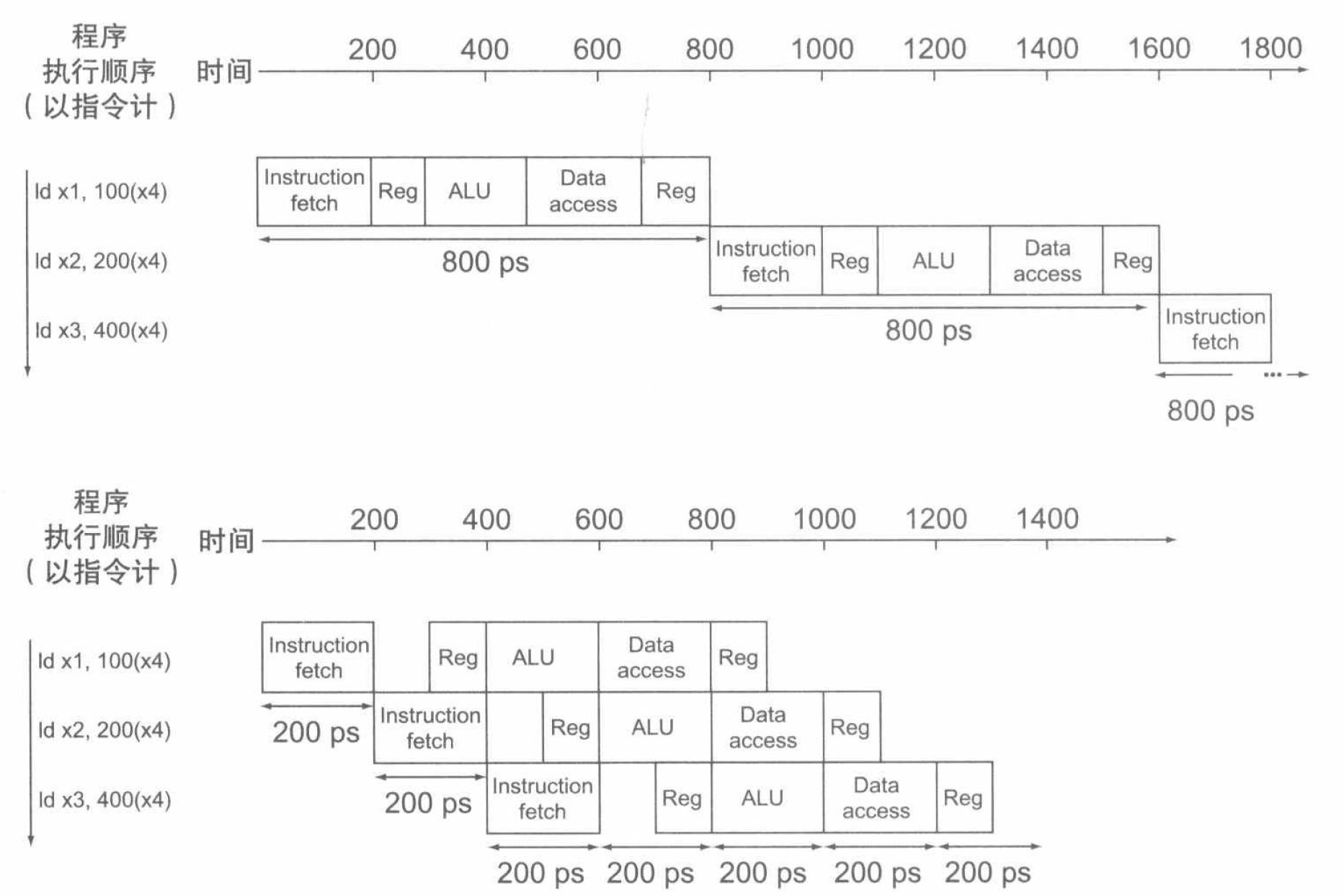
可见,尽管在每个功能单元执行的每一步时间没有减少,但是指令的平均执行时间却从 \(800 \mathrm{ps}\) 降低到了 \(200 \mathrm{ps}\),即提供了 \(4\) 倍的性能改进。
我们可以将这种性能加速比归纳为一个公式。如果流水线各阶段操作平巷,那么在理想条件下,流水线处理器上的指令执行时间满足
也就是说,在理想的条件和有大量指令的情况下,流水线带来的加速比约等于流水线级数。
流水线技术通过提高指令吞吐率来提高性能,而不是减少单个指令的执行时间。因此指令吞吐率是评估流水线性能的重要指标。
流水线冒险
那么我们现在就开始考虑真正的流水线设计中可能遇到的问题。一个容易想到的情况就是,在下一个时钟周期中下一条指令无法执行。这种情况被称作冒险 (hazard),具体来说有三种情况。
结构冒险
第一种冒险称作结构冒险 (structural hazard),即硬件不支持多条指令在同一时钟周期执行。
当然,RISC-V 指令系统是面向流水线设计的,这使得设计人员在多数情况下容易避免结构冒险。唯一可能面对的情况是,硬件的数量有限导致对同一硬件的复用。但总的来说是容易处理的。
数据冒险
第二种冒险称作数据冒险 (data hazard),即由于一个步骤必须等待另一个步骤完成而导致的流水线停顿。
在计算机流水线中,数据冒险源于一条指令依赖于前面一条尚在流水线中的指令。在不做任何干预的情况下,数据冒险通常会严重地阻碍流水线。
一种基本的解决方案是基于一个发现,即不需要等待指令完成就可以尝试解决数据冒险。这通过向内部资源添加额外的硬件,以提前从缓冲区中取到后一步需要的数据,而不是等到前一个指令执行完毕,数据到达程序员可见的寄存器或存储器。这种方法称作前递 (forwarding) 或旁路 (bypassing)。
我们来看这样一个例子,对于以下两条指令:
add x1, x2, x3 sub x4, x1, x5我们如下图这样来构造流水线:
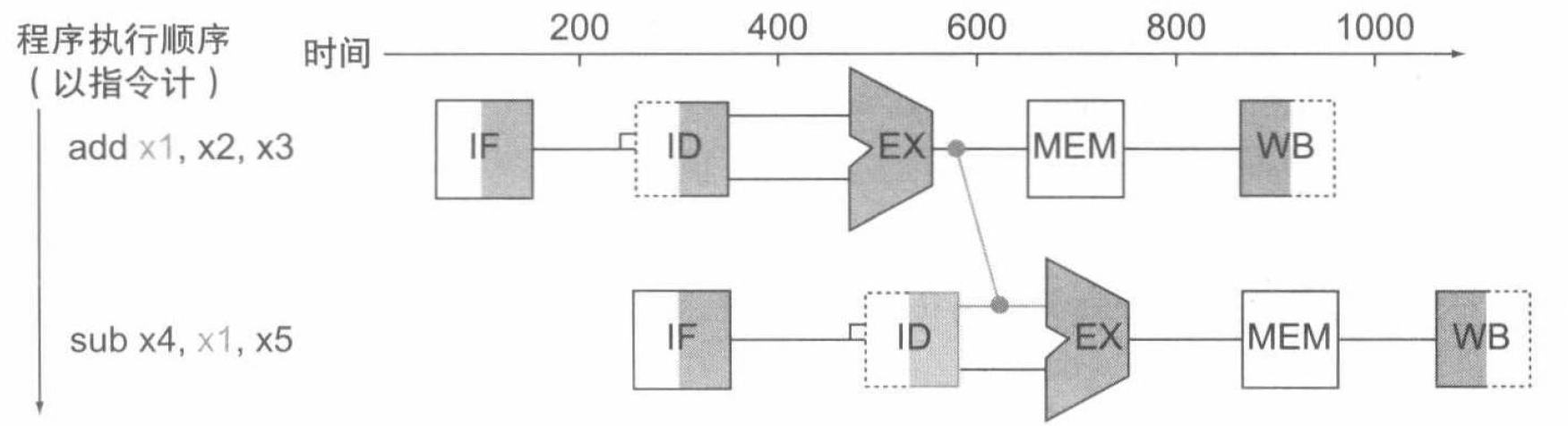
即将
add指令 EX 阶段的输出前递到sub指令 EX 阶段的输入,替换sub指令在第二阶段读出的寄存器x1的值。
当然,尽管前递的效果很好,但是不能避免所有的流水线停顿,仅当目标阶段在时间上晚于源阶段时,前递路径才有效。这种问题通常出现在载入-使用型数据冒险 (load-use data hazard) 中,对应于我们考察的指令就是在后一条指令中使用了前一条 ld 指令的载入值。因此,这种情况下流水线也不得不停顿一个阶段来应对,如下图:
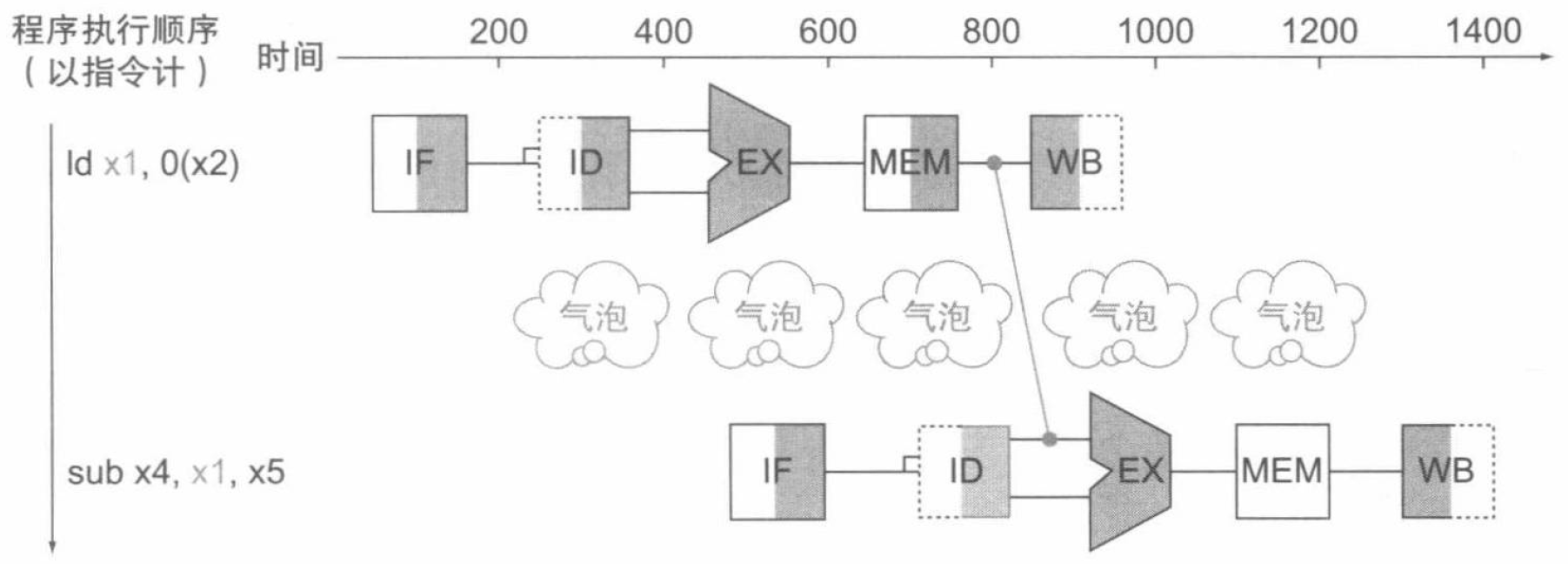
这张图中包含了流水线的一个重要概念,即流水线停顿 (pipeline stall),也通常称作气泡 (bubble)。在之后的章节我们会详细介绍如何解决这类冒险。
控制冒险
第三种冒险称作控制冒险 (control hazard),即一个步骤如何执行需要根据另一个步骤的执行结果,而那个步骤还未执行完毕。
容易意识到,这种问题主要出现在条件分支指令的处理上。解决这类冒险的主要方法是预测 (prediction),即假设一个预期结果,并按照预期结果先行流水线执行之后的步骤。如果实际的执行结果和预期不同,再重新开始执行对应的后续步骤。这样,处理器就仅在预期结果不正确的时候,才会发生停顿。
显然,这个方法的有效性取决于预测的正确性。在当下,成熟的分支预测可以预测一些条件分支指令发生跳转,而另一些不发生跳转。更进一步地,动态硬件预测其可以根据每个条件分支指令的行为进行预测,并在程序生命周期内可能改变条件分支的预测结果,并根据最近的成功预测调整下一次的预测。
这种动态预测的一种常用实现方法是保存每个条件分支是否发生分支的历史记录然后根据最近的过去行为来预测未来。在后面的章节我们将指出,当历史记录的数量和类型足够多时,动态分支预测器的正确率可以达到 \(90\%\)。
小结
流水线技术是一种在顺序指令流中开发指令间并行性 (parallelism) 的技术。与多处理器编程相比,其优点在于它对程序员是不可见的。
在接下来,我们将开始详细地介绍,对于上述各种问题的具体技术处理方式。
流水线数据通路和控制
流水线的图形化表示
首先,我们给出两种流水线图。我们以下述指令为例进行说明:
ld x10, 40(x1)
sub x11, x2, x3
add x12, x3, x4
ld x13, 48(x1)
add 14, x5, x6
第一种是多时钟周期流水线图 (multiple-clock-cycle pipeline diagram),如下:
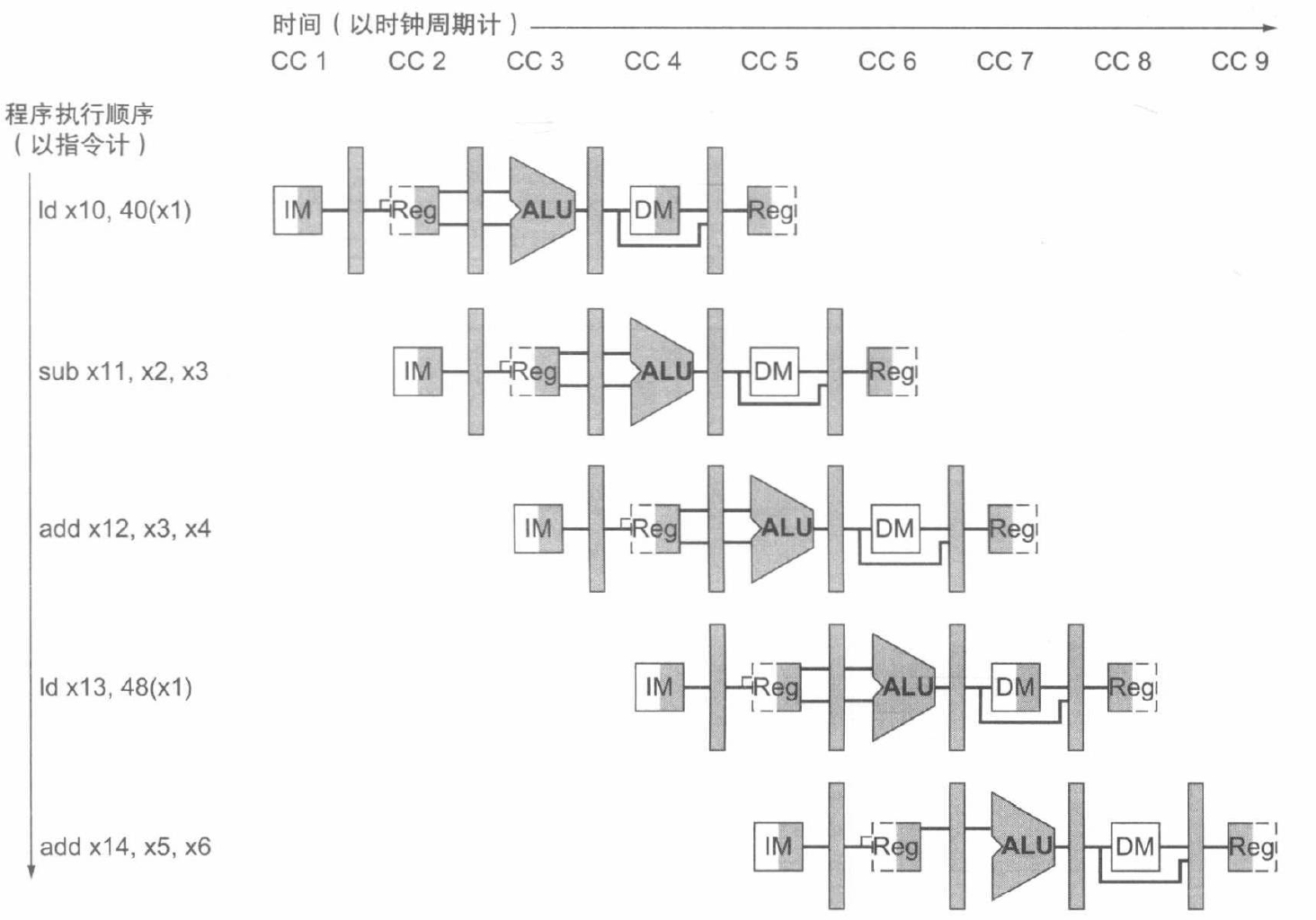
其中,图形的左半边阴影表示写入,右半边阴影表示读取,全阴影表示两者皆有,无阴影表示实际上不经过该阶段。
第二种是单时钟周期流水线图 (single-clock-cycle pipeline diagram),下图是上述指令流程中第 5 个时钟周期的单时钟周期图:
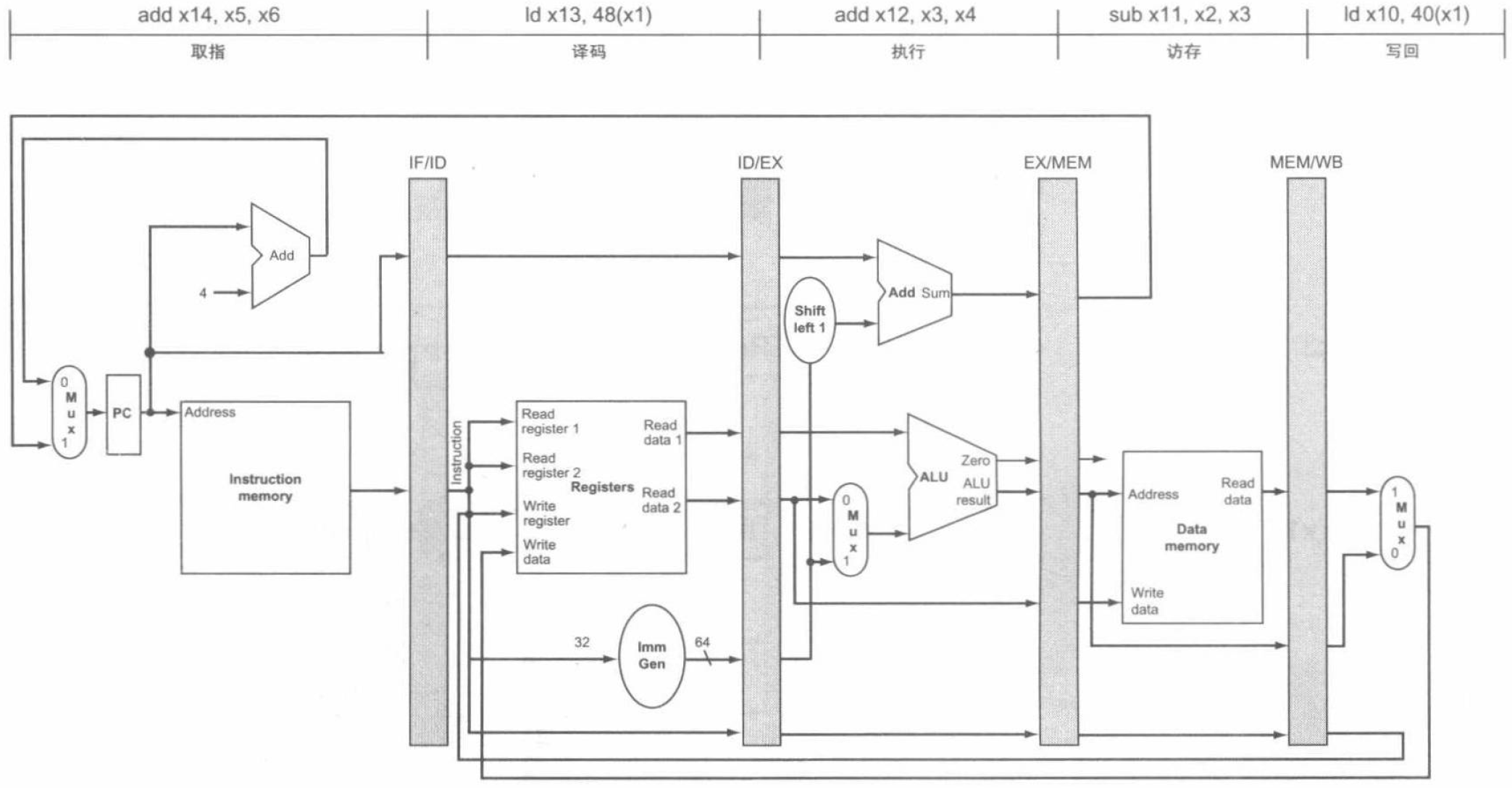
流水线控制
现在我们要将控制添加到流水线数据通路中,这一部分可以类比我们在单周期处理器中的做法。
第一步是在现有的数据通路上标记控制线,与单周期实现的情况一样,我们假定 PC 在每个时钟周期被写入,因此 PC 没有单独的写入信号。同理,流水线寄存器(IF/ID、ID/EX、EX/MEM 和 MEM/WB)也没有单独的写入信号,因为流水线寄存器也在每个时钟周期内都被写入。
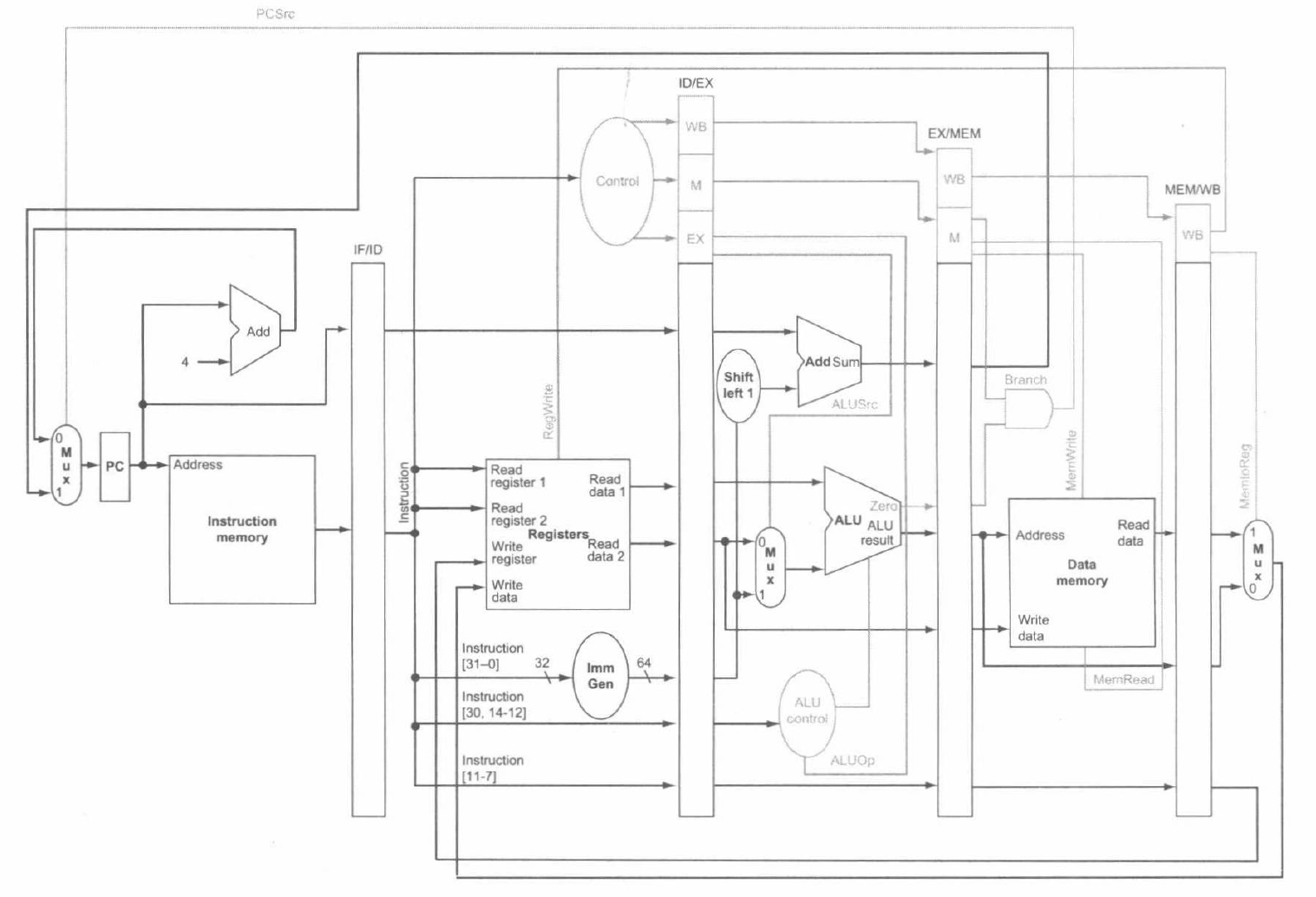
为了详细说明流水线的控制,我们需要在每个流水现阶段上设置控制值。由于每条控制线都只与一个流水线阶段中的功能部件相关,因此我们可以根据流水线阶段将控制线也划分成 5 组:
- 取指:读指令存储器和写 PC 的控制信号总是有效的,因此在这个阶段没有什么需要特别控制的内容。
- 指令译码 / 读寄存器堆:在 RISC-V 指令格式中两个源寄存器总是位于相同的位置,因此在这个阶段也没有什么需要特别控制的内容。
- 执行 / 地址计算:要设置的信号是 ALUOp 和 ALUSrc,这个信号选择 ALU 操作,并将读数据 2 或者符号扩展的立即数作为 ALU 的输入。
- 存储器访问:本阶段要设置的控制线是 Branch、MemRead 和 MemWrite。这些信号分别由相等则分支、加载和存储指令设置。除非控制电路标示这是一条分支指令并且 ALU 的输出为 \(0\),否则将选择线性地址的下一条指令作为 PCSrc 信号。
- 写回:两条控制线是 MemtoReg 和 RegWrite,MemtoReg 决定是将 ALU 结果还是将存储器值发送到寄存器堆中,RegWrite 写入所选值。
下图显示了具有扩展流水线寄存器并且将控制线连接到相应流水线阶段的完整数据通路。
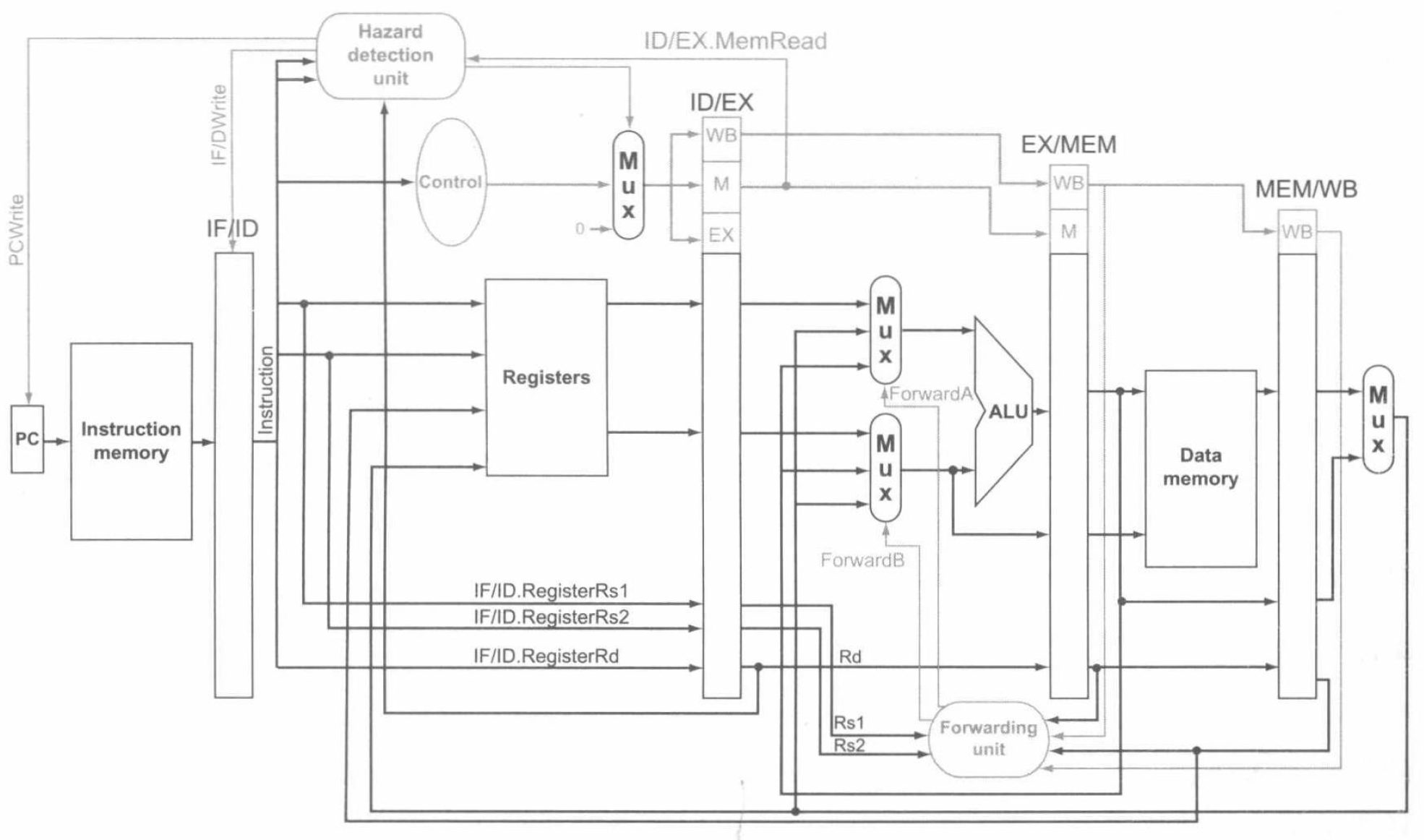
数据冒险的处理
前递
前面我们已经指出,数据冒险是流水线执行的关键阻碍。本节我们将详细讨论处理数据冒险的方法。我们将基于下面这样一个指令序列的示例进行讨论:
sub x2, x1, x3 // Register x2 written by sub
and x12, x2, x5 // 1st operand(x2) depends on sub
or x13, x6, x2 // 2nd operand(x2) depends on sub
add x14, x2, x2 // 1st(x2) & 2nd(x2) depend on sub
sd x15, 100(x2) // Base(x2) depends on sub
后 4 条指令都相关于第一条指令中得到的存放在寄存器 x2 中的结果。这个指令序列是这样在流水线中运行的:
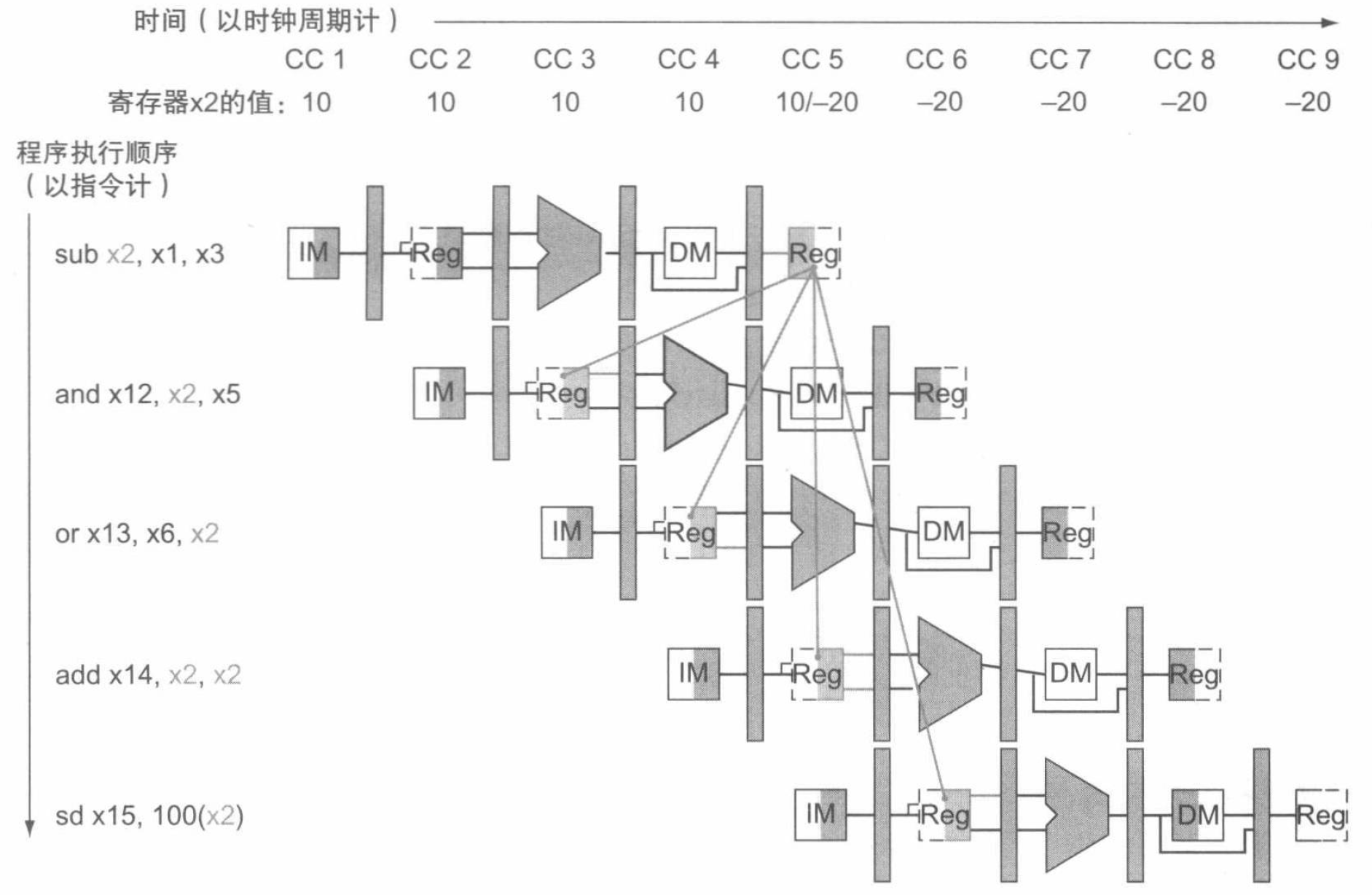
图中的连线表示了数据冒险具体发生的位置。通过分析寄存器间的时序关系,我们可以得到这样两对冒险的条件:
- (a) \(\texttt{EX/MEM.RegisterRd} = \texttt{ID/EX.RegisterRs1}\) (b) \(\texttt{EX/MEM.RegisterRd} = \texttt{ID/EX.RegisterRs2}\)
- (a) \(\texttt{MEM/WB.RegisterRd} = \texttt{ID/EX.RegisterRs1}\) (b) \(\texttt{MEM/WB.RegisterRd} = \texttt{ID/EX.RegisterRs2}\)
落实到示例中,可以发现 sub 和 and 指令之间存在类型为 1a 的冒险,sub 和 or 指令之间存在类型为 2b 的冒险。
但是,因为并不是所有的指令都会写回寄存器,所以在上述两对条件外,还要再加入额外的条件才能确定合适进行前递。首先,要检查 EX 和 MEM 阶段的 WB 控制字段以确定 RegWrite 信号,即 EX/MEM.RegWrite 和 MEM/WB.RegWrite 是否有效。其次,如果流水线中的指令以 x0 作为目标寄存器,我们希望避免前递非零的结果值。于是对应地,我们将 \(\texttt{EX/MEM.RegisterRd} \neq 0\) 添加到第一类冒险条件,将 \(\texttt{MEM/WB.RegisterRd} \neq 0\) 添加到第二类冒险条件,即可使得上述条件正常工作。
现在我们可以检测冒险了,我们来看一看得到的正确前递后的指令序列在流水线中的运行:
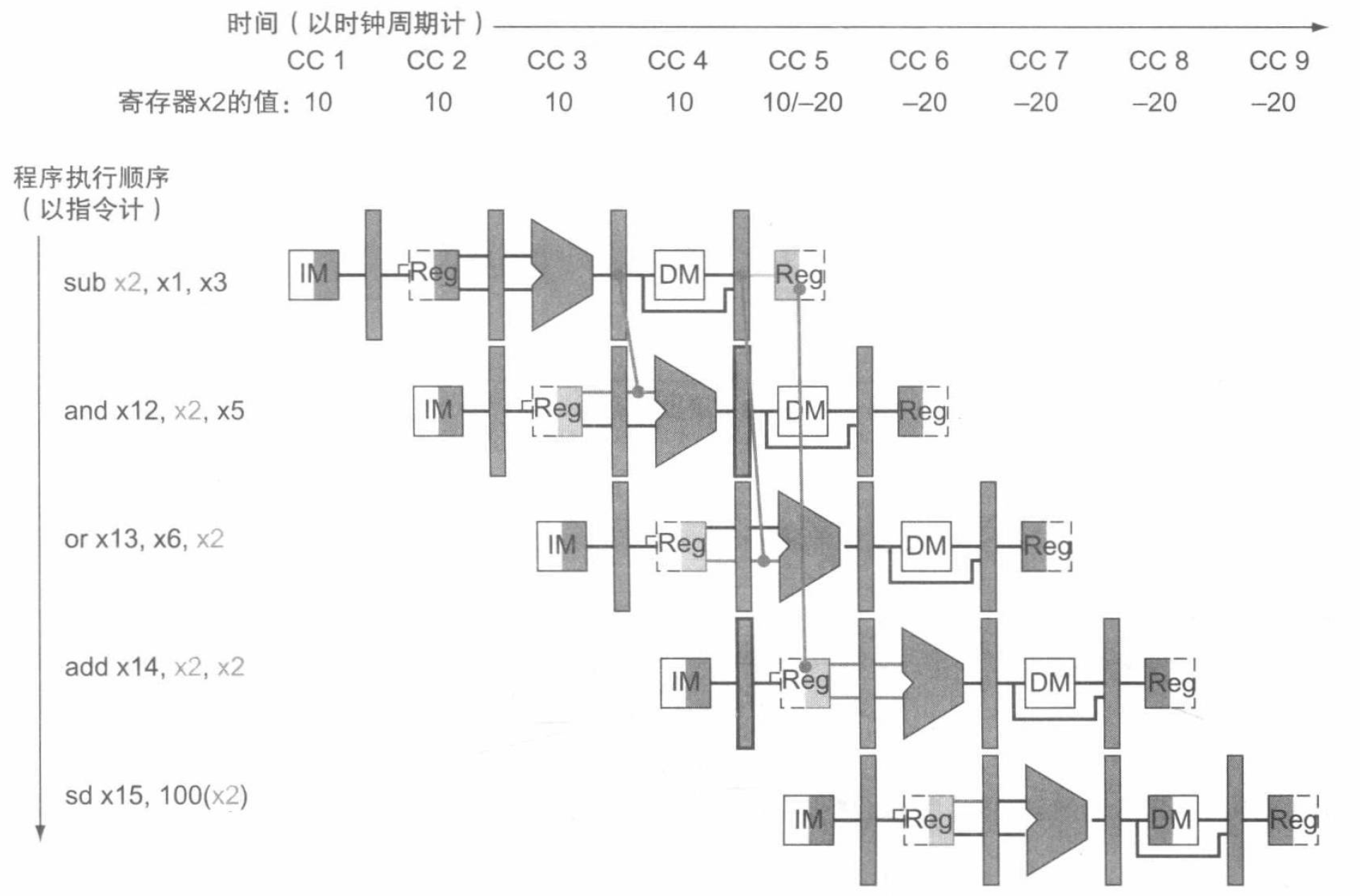
现在,我们给出通过前递解决冒险的数据通路:
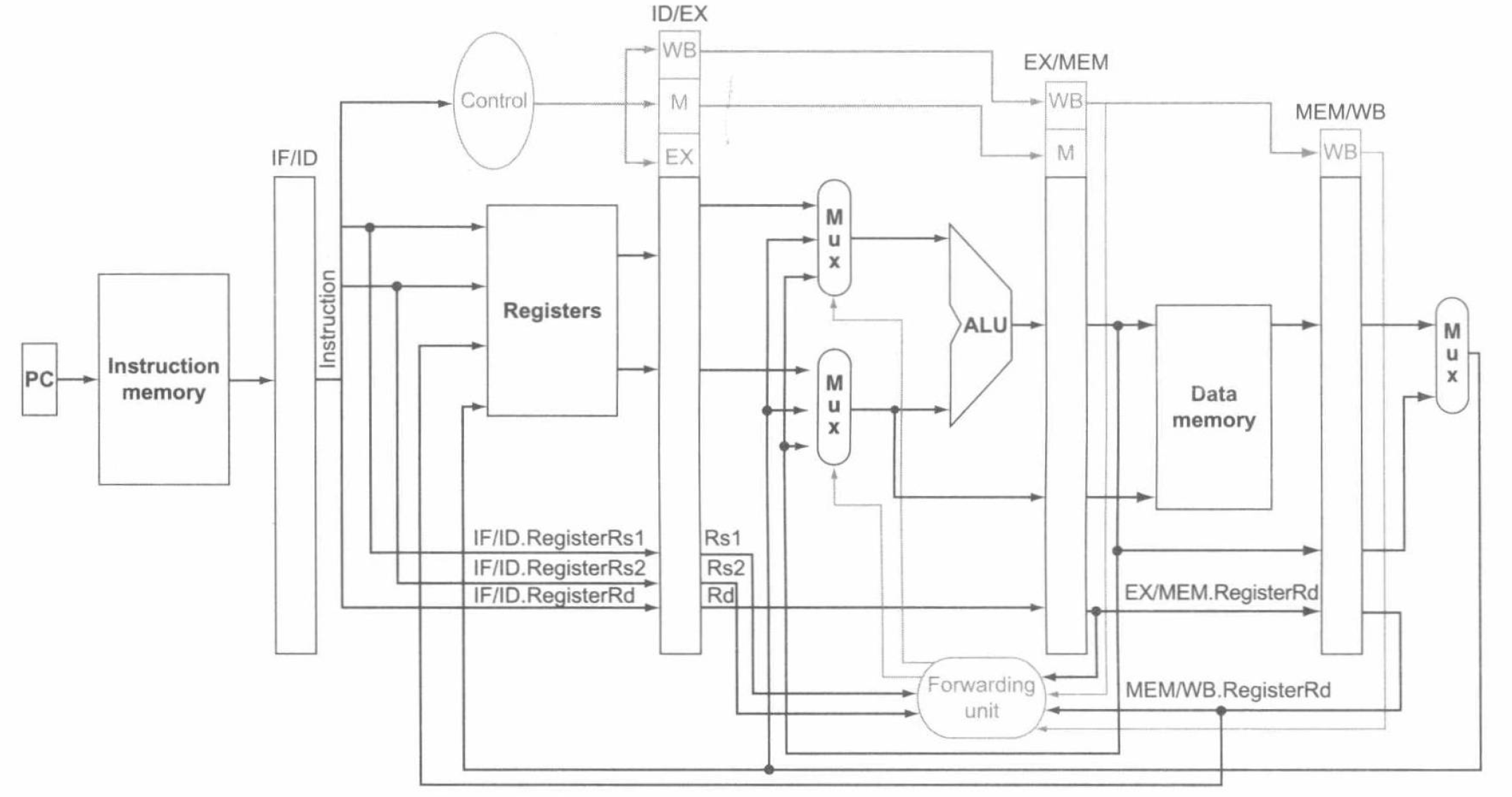
其中多选器的控制值如下:

并且,我们可以给出检测冒险的条件以及解决相应冒险的控制信号:
-
EX 冒险
if (EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs1)) ForwardA = 10 if (EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs2)) ForwardB = 10 -
MEM 冒险
if (MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0) and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs1)) and (MEM/WB.RegisterRd = ID/EX.RegisterRs1)) ForwardA = 01 if (MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0) and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs2)) and (MEM/WB.RegisterRd = ID/EX.RegisterRs2)) ForwardB = 01
可以注意到,MEM 冒险需要保证在不发生 EX 冒险时才发生。
停顿
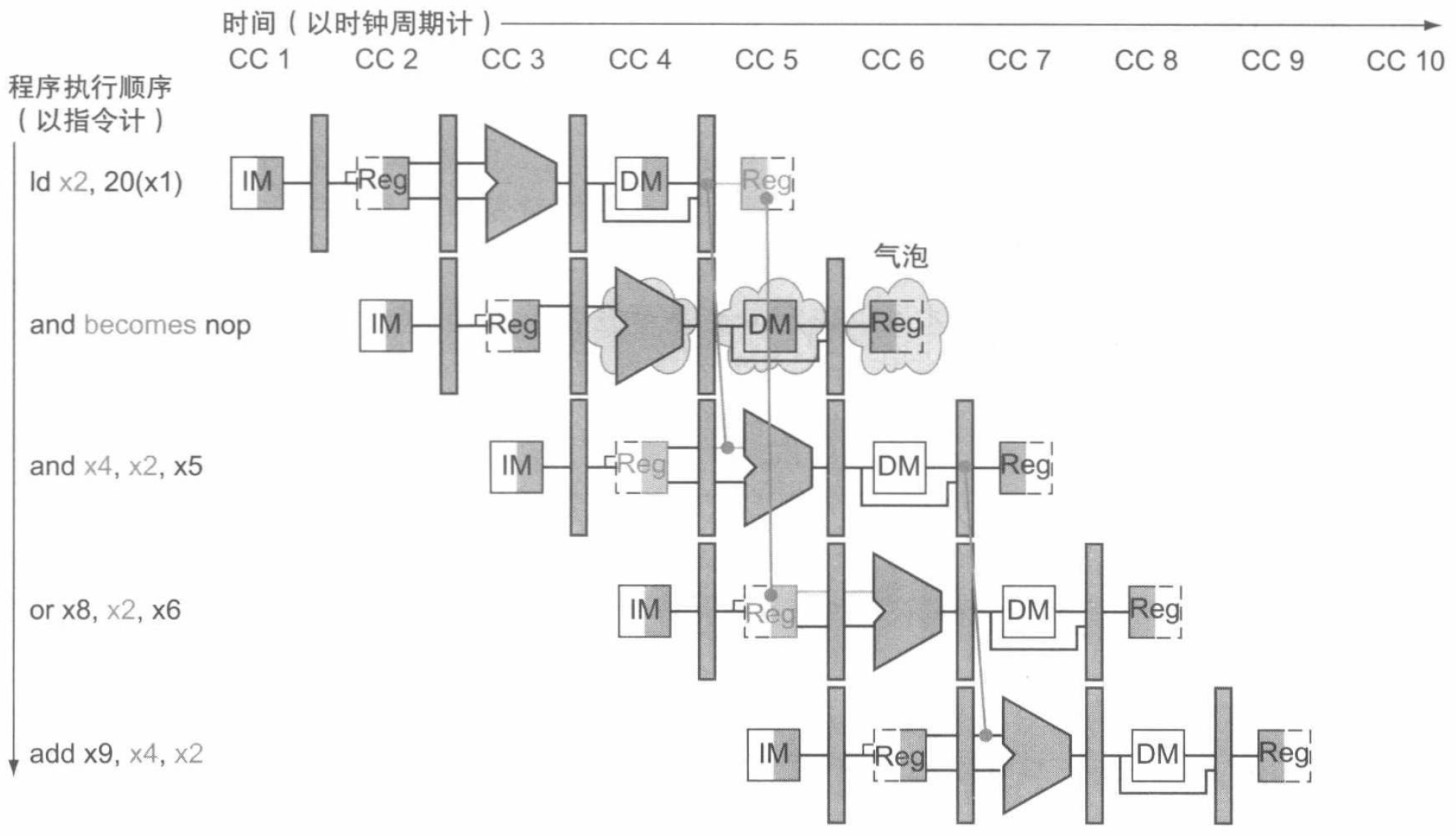
当一条指令试图在加载指令写入一个寄存器之后读取这个寄存器时,前递不能解决此处的冒险。下面这样一个例子就表明了这一问题:
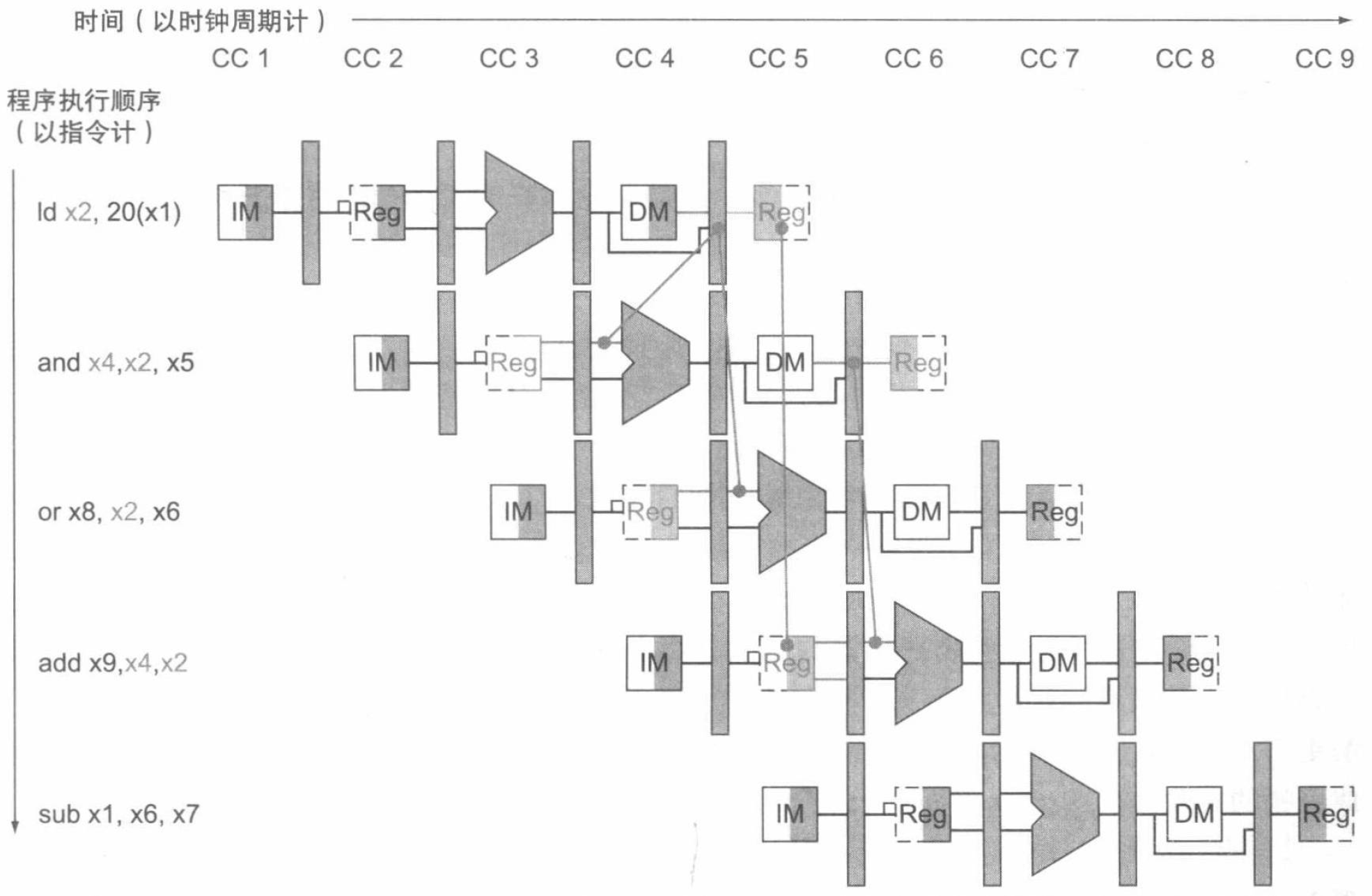
可见,当加载指令后跟着一条需要读取加载指令结果的指令时,流水线必须被阻塞以消除这种指令组合带来的冒险。因此,除了一个前递单元外,还需要一个冒险检测单元。该单元在 ID 流水线阶段操作,从而可以在加载指令和相关加载指令结果的指令之间加入一个流水线阻塞。这个单元检测加载指令,冒险控制单元的控制逻辑满足如下条件:
if (ID/EX.MemRead
and ((ID/EX.RegisterRd = IF/ID.RegisterRs1)
or (ID/EX.RegisterRd = IF/ID.RegisterRs2)))
stall the pipeline
如果处于 ID 阶段的指令被停顿了,那么在 IF 阶段中的指令也一定要被停顿,否则已经渠道的指令就会丢失。这需要我们将某些指令替换为空指令 (nops) 来实现。现在,我们可以来看一看开头那个需要插入停顿的例子应该如何运行:
同时,我们给出完整的具有 2 个前递多选器、1 个冒险检测单元和 1 个前递单元的流水线控制图:
控制冒险的处理
另一个常见的流水线冒险发生在条件分支,也就是控制冒险或分支冒险。下图展示了一个发生控制冒险的例子:
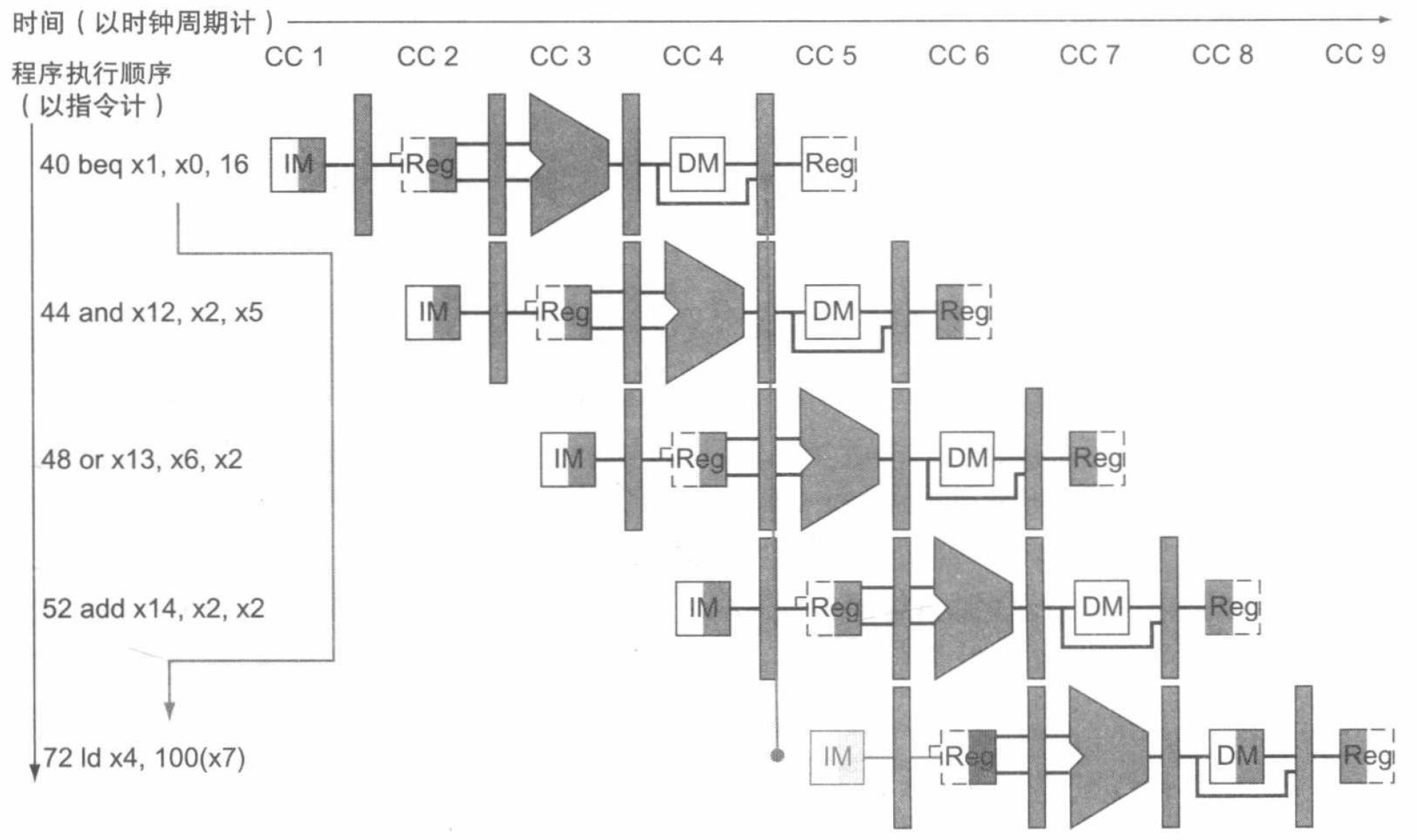
接下来将介绍两种解决控制冒险的方案和一种提升解决方案性能的优化方法。
假设分支不发生
一种提升分支阻塞效率的方法是预测条件分支不发生并持续执行顺序指令流。一旦条件分支发生,已经被读取和译码的指令就将被丢弃,流水线继续从分支目标处开始执行。如果条件分支不发生的概率很大(例如循环的跳出),同时丢弃指令的代价又很小,那么这种优化方式带来的提升是显著的。
想要丢弃指令,只需要将初始控制值变为 \(0\) 即可。具体来说,这需要我们改变当分支指令到达 MEM 阶段时 IF、ID 和 EX 阶段的 3 条指令,也就是清除 (flush) 这 3 条指令。
缩短分支延迟
一种提升条件分支性能的方式是减少发生分支时所需的代价。到目前为止,我们假定分支所需的下一 PC 值在 MEM 阶段才能被获取,但如果我们将流水线中的条件分支指令提早移动执行,就可以刷新更少的指令。
要将分支决定向前移动,需要两个操作提早发生:计算分支目标地址和判断分支条件。前者是相对简单的,因为在 IF/ID 流水线寄存器中就已经有 PC 值和立即数字段,所以只需将分支地址从 EX 阶段移动到 ID 阶段即可。困难的部分是分支决定本身。对于相等时跳转指令,这需要在 ID 阶段比较两个寄存器中的值是否相等。
具体来说,这里存在两个复杂的因素。一是需要在 ID 阶段将指令译码,决定是否需要将指令旁路至相等检测单元;二是在 ID 阶段分支比较所需的值可能在之后才会产生,因此可能会产生数据冒险,所以指令停顿也是必需的。
尽管这很困难,但是将条件分支指令的执行移动到 ID 阶段的确是一个有效的优化。为了清楚 IF 阶段的指令,我们添加了一条称作 IF.Flush 的控制线,它将 IF/ID 流水线寄存器中的指令字段设置为 \(0\)。将寄存器清空的结果是将已经取到的指令转换成一条 nop 指令,该指令不进行任何操作,也不改变任何状态。
动态分支预测
假定条件分支不发生是一种简单的静态预测机制,在复杂的流水线中,这种机制容易产生较大的性能浪费。于是相对地,我们尝试在程序执行的过程中,使用运行信息进行分支预测,这就是动态分支预测 (dynamic branch prediction)。
动态分支预测一般基于分支预测缓存 (branch prediction buffer) 和分支历史表 (branch history)。
最简单分支预测缓存只有 1 个比特位,即存储上一次该分支是否发生跳转,并据此预测下一次分支执行的情况。但是这个方案的缺点是明显的:即当一个条件分支发生状态变化时,会造成 2 次预测错误而不只 1 次。
一个有效的改进称作 2 位预测机制,即记录过去两次分支是否跳转,并只在连续两次预测错误时再改变预测。理论上,这种预测的正确率可以达到 \(75\%\)。这个过程可以表示为下图的状态自动机:
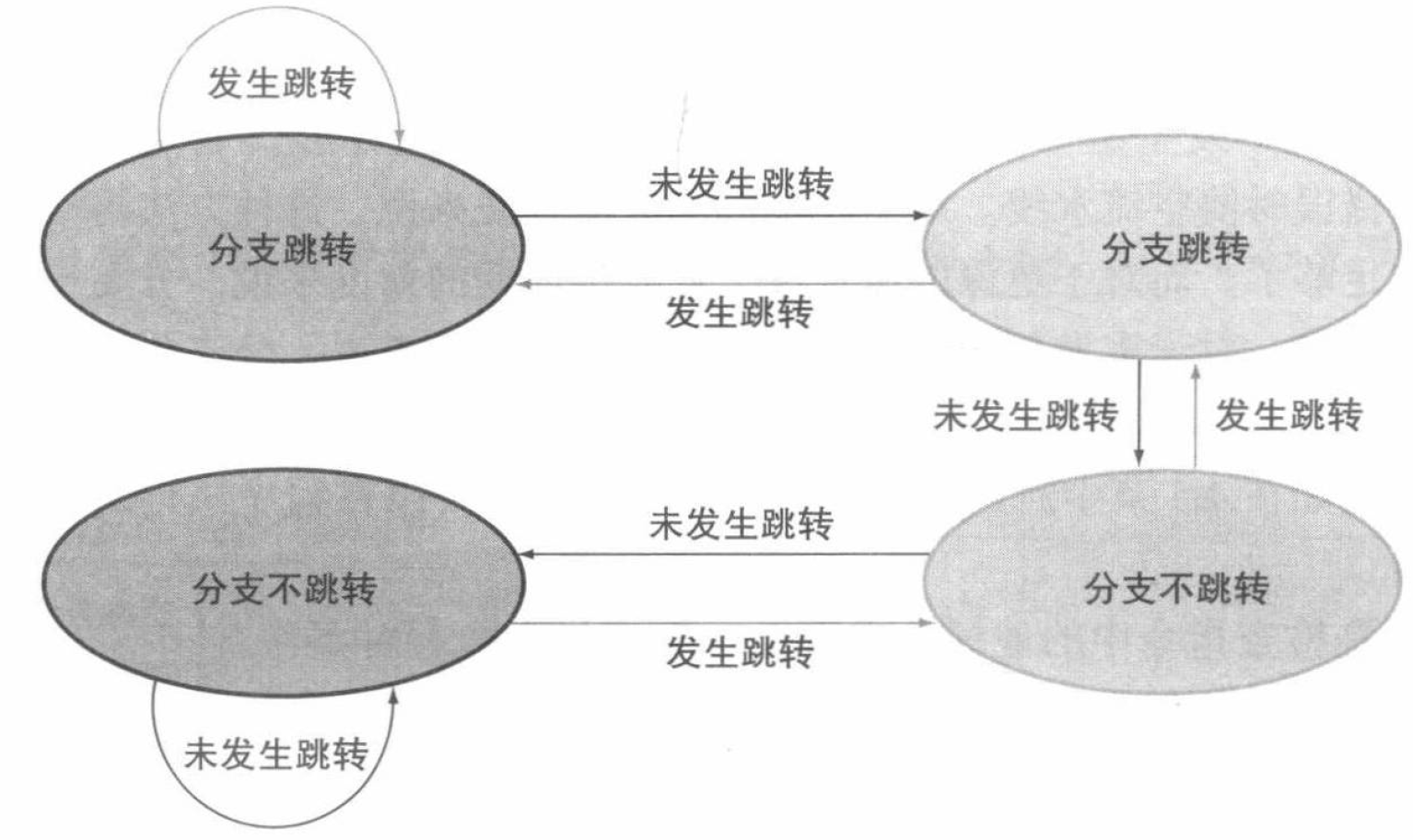
上述的两种预测器都称作相关预测器 (correlating predictors)。还有一种高级的预测器称作锦标赛分支预测器 (tournament branch predictor),就是对于每个分支使用多种预测器,记录它们累计的预测正确率,并总是采用其中最准确的那个作为预测结果。
到这里,我们已经基本讨论完了流水线处理器的基本架构,下图是综合的数据通路和控制图:
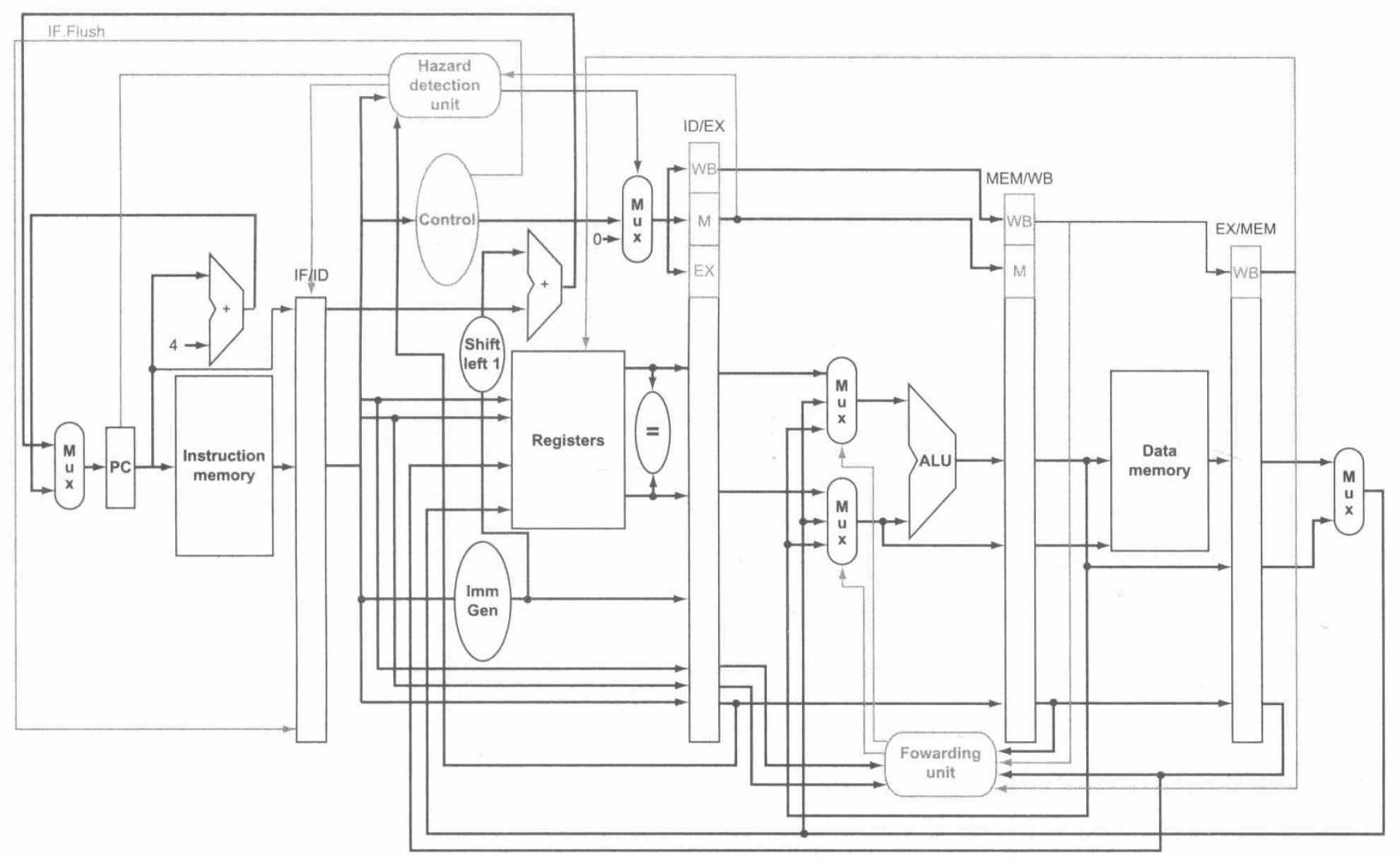
例外
控制逻辑是处理器设计中最有挑战的部分:验证正确性最为困难,同时也最难进行时序优化。例外 (exception) 和中断 (interrupt) 是控制逻辑需要实现的任务之一。除分支指令外,它式另一种改变指令执行控制流的方式。
RISC-V 中如何处理例外
在目前所讲过的实现中,只存在两种例外类型:未定义指令和硬件故障。
当例外发生时,处理器必须执行的基本动作是:在系统例外程序计数器 (Supervisor Exception Program Counter, SEPC) 中保存发生例外的指令地址,同时将控制权转交给操作系统。之后,操作系统将做出相应动作。完成例外处理的所有操作后,操作系统使用 SEPC 寄存器中的内容重启程序的正常执行。可能是继续执行源程序,也可能是终止程序。
操作系统进行例外处理,除了引发例外的指令外,还必须获得例外发生的原因。第一种方法,也是 RISC-V 中使用的方法是设置系统例外原因寄存器 (Supervisor Exception Cause Register, SCAUSE),该寄存器中记录了例外原因。另一种方法是使用向量式中断 (vectored interrupt),该方法用基址寄存器加上例外原因(作为偏移)作为目标地址来完成控制流转换,从而让操作系统根据例外向量起始地址来确定例外原因。
通过添加一些额外寄存器和控制信号,并稍微扩展控制逻辑,就可以完成对各种例外的处理。
流水线实现中的例外
流水线实现中,将例外处理看作是一种特殊的控制冒险。当例外发生时,我们需要在流水线上清除掉发生例外的指令后的指令,并从新地址开始取指。与处理分支指令不同的是,例外会引起系统状态的变化。
具体来说:
- 处理分支预测错误时,我们将取值阶段的指令变为空操作
nop,以此来消除影响。 - 对于进入译码阶段的指令,增加新逻辑控制译码阶段的多选器使输出为 \(0\),流水线停顿。添加一个新的控制信号 ID.Flush,它与来自于冒险检测单元的 stall 信号进行或运算,使用该信号对进入译码阶段的指令进行清除。
- 对于进入执行阶段的指令,我们使用一个新的控制信号 EX.Flush,使得多选器输出为 \(0\)。并预先指定一个例外入口地址(RISC-V 中为
0x0000 0000 1C09 0000)。为保证从正确地址开始取指,我们为 PC 多选器新增一个输入,保证能将上述例外入口地址送给 PC 寄存器。
加入了如上针对例外处理的改进后,我们的数据通路和控制信号如下图:
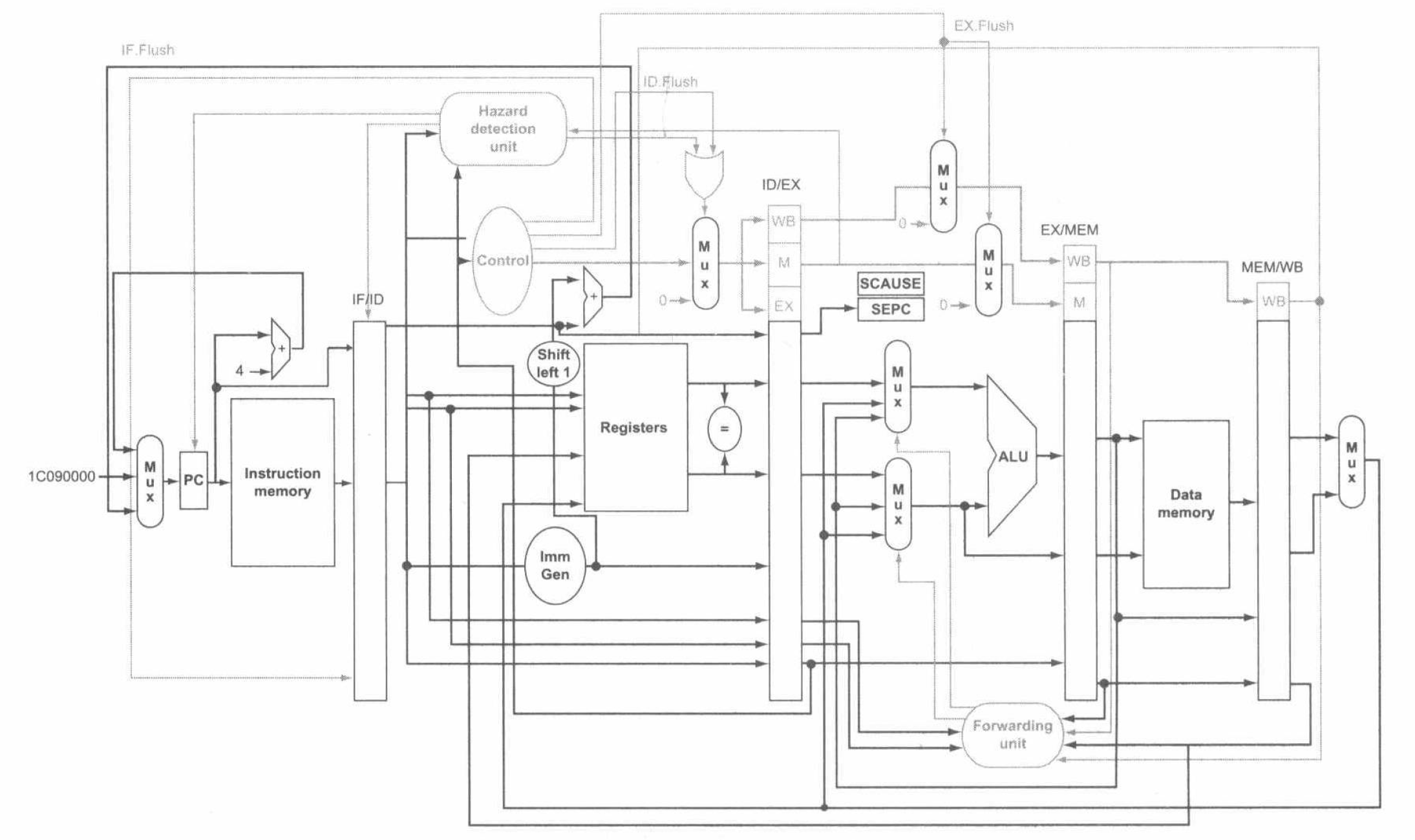
进一步地,同一个周期内可以同时发生多个例外。解决方案是,对例外进行优先级排列,便于判断服务顺序。在 RISC-V 中,这一步骤由硬件实现。最后,SPEC 寄存器保存引发例外的指令的地址,SCAUSE 寄存器记录当前最高优先级的例外信息。
指令间的并行性
流水线技术挖掘了指令间潜在的并行性,这被称作指令级并行 (instruction-level parallelism, ILP)。提高指令级并行度主要有两种方法。第一种是增加流水线的级数,让更多的指令重叠执行。另一种提到指令并行度的方法是增加流水线内部的功能部件数量,这样可以每周期发出多条指令,这种技术称作多发射 (multiple issue)。
每周期发射多条指令,可以使得指令执行频率超过时钟频率。实现多发射处理器主要有两种方法,区别在于编译器和硬件的不同分工。如果指令发射与否的判断是在编译时完成的,就称作静态多发射 (static multiple issue)。如果指令发射与否的判断是在动态执行过程中由硬件完成的,就称作动态多发射 (dynamic multiple issue)。
推测
推测 (speculation) 是一种非常重要的深度挖掘指令级并行的方法。以预测思想为基础,推测方法允许编译器或处理器来「猜测」指令的行为,并允许其它于被推测指令相关的指令提前开始执行。
推测可以在编译时完成,也可以在执行时由硬件完成。但是无论是在何时推测,实现推测错误时的恢复机制非常困难。而且推测式执行还会引入另一个问题,即对某条指令进行推测可能引入不必要的例外。总而言之,不恰当的推测可能会反而降低处理器的性能。因此,正确的、有效的推测技术是推测能够改善处理器性能的关键。
静态多发射
静态多发射处理器是由编译器来支持指令打包和处理指令间的冒险。对于静态多发射处理器,可以将同一周期发射出去的指令集合,即发射指令包 (issue packet) 看成一条需要进行多种操作的「大指令」,这正符合超长指令字 (Very Long Instruction Word, VLIW) 的设计思路。
静态多发射处理器对于潜在的数据和控制冒险有不同的解决方案。在一些设计实现中,由编译器来实现所有冒险的解决、代码的调度以及插入相应的 nop;而在另一些设计实现中,使用硬件来检测两个指令包之间的数据冒险,并产生相应的流水线停顿。后文我们假设使用的是第二种方法。
如果想同时发射 ALU 和数据传输类指令,除了上文所说的冒险检测和流水线停顿逻辑,首先需要添加的硬件资源是寄存器堆的读写口,为 ALU 指令和数据传输类指令提供两套不同的数据通路以避免结构冒险。如下图:
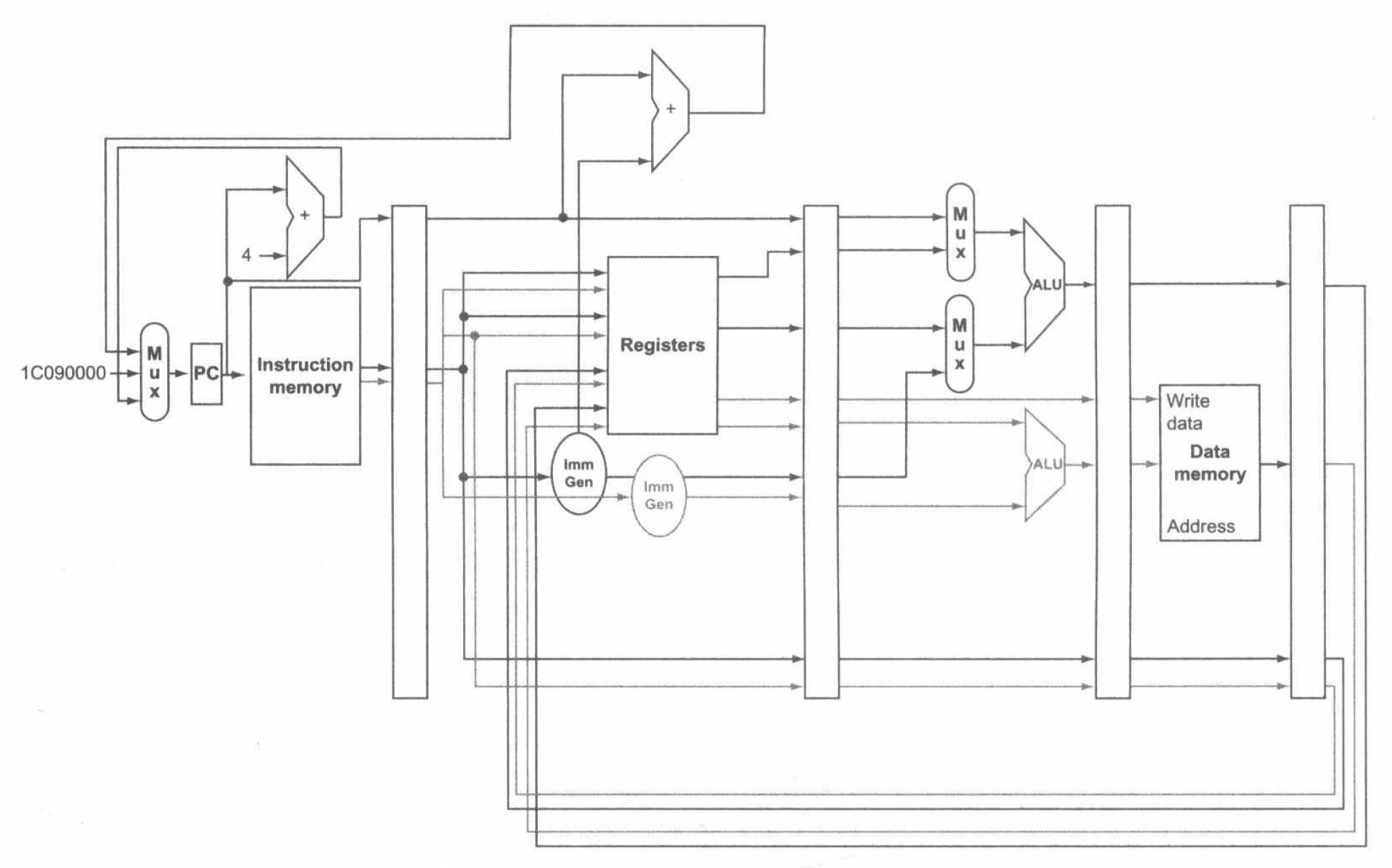
基于这个设计,我们来看一个具体的双发射流水线的例子。
对于以下指令:
Loop: ld x31, 0(x20) // x31 = array element add x31, x31, x21 // add scalar in x21 sd x31, 0(x20) // store result addi x20, x20, -8 // decrement pointer blt x22, x20, Loop // branch if x20 > x22我们假设可以被分支是可以被预测的,也就是控制冒险由硬件解决。于是观察指令,发现前三条指令具有数据相关,因此重点调度后两条。具体来说,我们可以这样调度:

于是就将 CPI 从 \(1\) 降到了 \(0.8\)。需要注意的是,由于出现了调度,所以
sd指令的访存地址要发生变化,在例子中要加上 \(8\)。
但这个设计仍然有一些问题。例如,在简单五级流水线结构中,load 指令有一个周期的使用延迟 (use latency),而 ALU 指令本来是没有使用延迟的。但在双发射流水线中,需要同时发射 ALU 指令和 load 指令。如果这两条指令存在数据冒险,则 load 指令不能被发射,相当于 ALU 指令增加了一个周期的使用延迟。
于是我们还要进一步提高程序性能。循环展开 (loop unrolling) 是一种专门针对循环体提高程序性能的重要编译技术。它将循环体展开多遍,从不同循环中寻找可以重叠执行的指令来挖掘更多的指令级并行性。
我们继续沿用上文的例子。
我们将循环体展开 4 遍,完成重叠后再消除不必要的开销,就可以得到这样的调度结果:
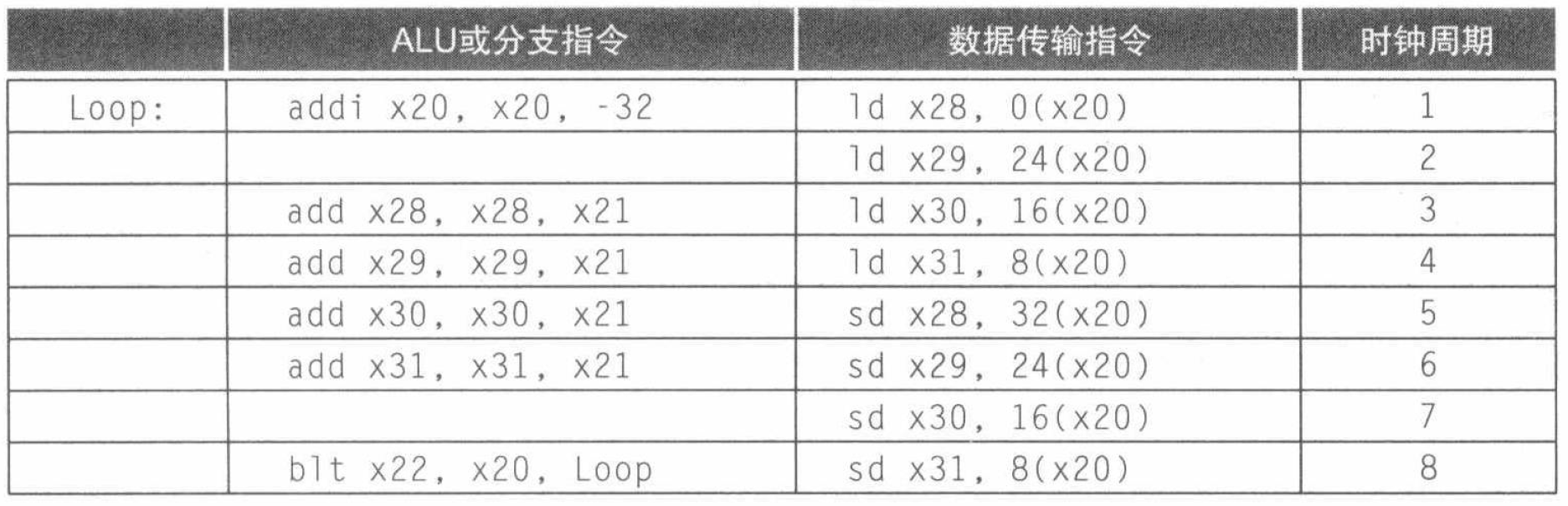
与上一个例子同理,
ld指令的访存地址也要发生变化,先使用x20的原值,然后将地址减 \(8\)、减 \(16\)、减 \(24\)。
从例子中我们可以发现,在循环展开的过程中,编译器使用了额外的寄存器,这一行为称作寄存器重命名 (register renaming)。
可以发现,不同循环的指令之间是没有数据依赖的,仅仅是由于名称复用导致潜在的冒险,这种情况被称作反相关 (antidependence) 或名字相关 (name dependence)。寄存器重命名就能解决这个问题,在循环展开时对寄存器进行重命名,可以允许编译器移动不同循环中的指令,以更好地调度代码。
当然,寄存器重命名可以消除名字相关,但不能消除真相关。
动态多发射
动态多发射处理器也称作超标量 (superscalar) 处理器或朴素的超标量处理器。在最简单的超标量处理器中,指令按顺序发射,由硬件来判断当前周期可以发射的指令数:是一条还是更多条,或者停顿发射。显然,如果想让这样的处理器活得更到的性能,仍然需要编译器进行指令调度,消除掉指令间的相关,提高指令的发射率。
许多超标量处理器扩展了动态发射逻辑的基础框架,形成了动态流水线调度 (dynamic pipeline scheduling) 技术。动态流水线调度技术由硬件逻辑选择当前周期内执行的指令,并对指令进行重排以尽量避免流水线的冒险和停顿。
在动态调度中,流水线被分成 3 个主要部分:取指和发射单元、多功能部件、提交单元 (commit unit)。下图给出了这种流水线的基本模型:
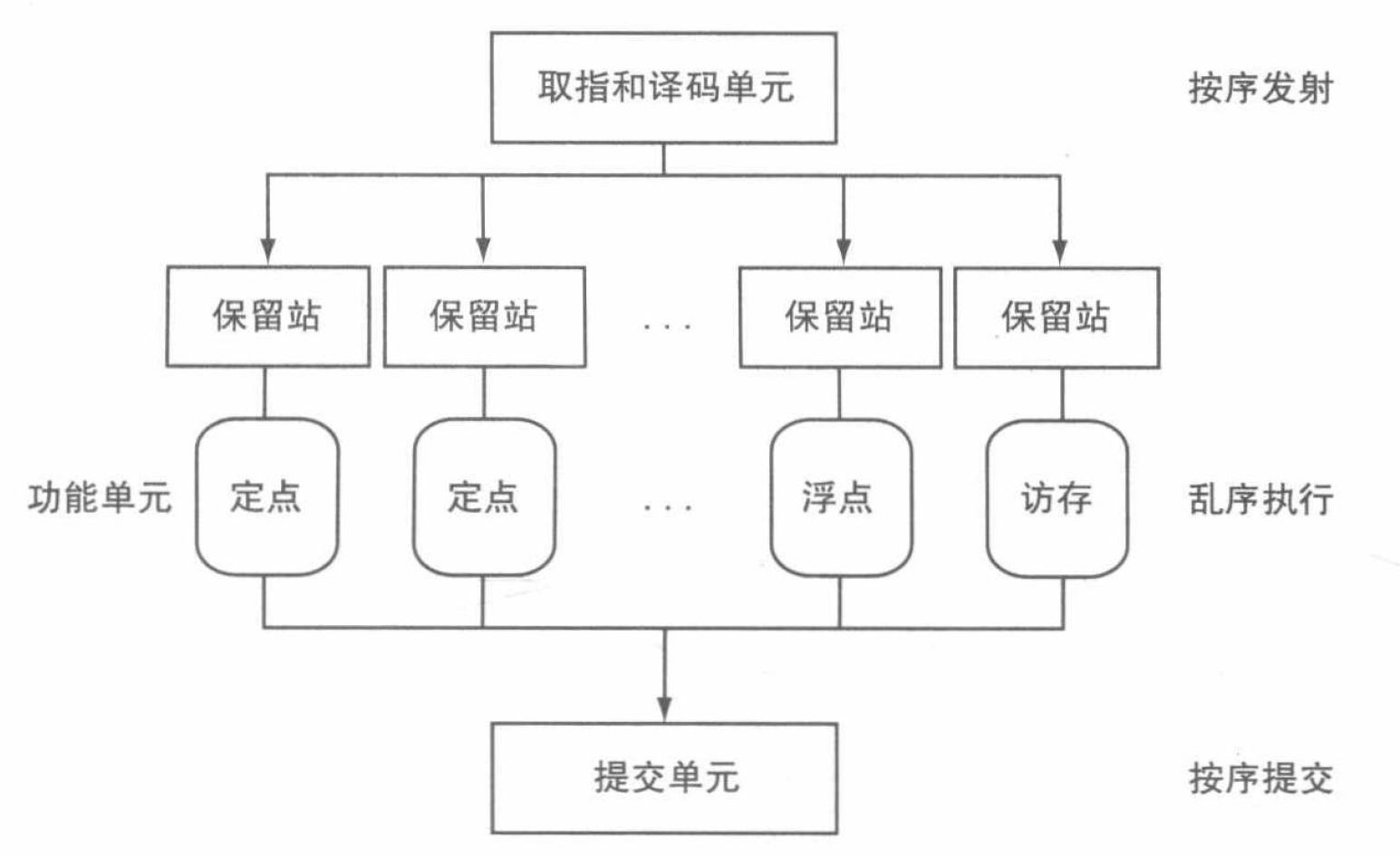
由图可见,取值和发射单元负责取指令、译码、将各指令发送到相应的功能单元上执行。每一个功能单元前都有若干缓冲区,称为保留站 (reservation stations)。保留站中存放指令的操作和所叙的操作数。只要缓冲区中指令所需操作数准备好,并且功能单元就绪,就可以执行指令。一旦指令执行结束,结果将被传送给保留站中正在等待使用该结果的指令,同时也传送到提交单元中进行保存。提交单元中保存了已完成指令的执行结果,并在真正提交时才使用它们更新寄存器或者写入内存。这些位于提交单元的缓冲区,通常被称作重排序缓冲 (reorder buffer)。和静态调度流水线中的前递逻辑一样,重排序缓冲也可以用来为其它指令提供操作数。一旦指令提交,寄存器得到更新,就和正常流水线一样直接从寄存器获取最新的数据。
在保留站中保存操作数,以及重排序缓冲中保存运算结果,两者共同提供了一种寄存器重命名方式。考虑一下步骤:
- 发射指令时,指令会被拷贝到相应功能单元的保留站中。同时,如果指令所需的操作数已准备好,也会从寄存器堆或者重排序缓冲中拷贝到保留站中。指令会一直保存在保留站中,指导所叙的操作数全部准备好,并且相应功能部件可用。对于处在发射阶段的指令,由于可用操作数已被拷贝至保留站中,他们在寄存器堆中的副本就无须保存了,如果出现相应寄存器的写操作,那么该寄存器中的数值将被更新。
- 如果操作数不在寄存器堆或者重排序缓冲中,那它一定在等待某个功能单元的计算结果。该功能单元的名字将被记录。当最终结果计算完毕,将会直接从功能单元拷贝到等待该结果的保留站中,即直接旁路了寄存器堆。
从概念上讲,可以把动态调度流水线看作程序的数据流结构分析。处理器在不违背程序员有的数据流顺序的前提下以某种顺序执行指令,被称作乱序执行 (out-of-order execution)。这是因为这样执行的指令顺序和取指的顺序是不同的。
为使得程序行为与简单的按序单发射流水线一致,乱序执行流水线的取指和译码都需要按需执行,一边正确处理指令间的相关。同样,提交阶段也需要按照取指的顺序依次将指令执行的结果写入寄存器和存储中。这种保守的处理方法称作按序提交 (in-order commit)。如果发生例外,处理器很容易就能找到例外前的最后一条指令,也会保证只更新在此之前的指令需要改写的寄存器。
总的来说,虽然流水线的前端(取指和译码阶段)和后端(提交阶段)都是按序执行,但是功能部件是允许乱序执行的。任何时候只要所需数据准备好,指令就可以被发射到功能部件上开始执行。